 Jenkins中pipeline对接CMDB接口获取主机列表的发布实践
Jenkins中pipeline对接CMDB接口获取主机列表的发布实践
# 1,前言
发布平台统一项目中,二丫 (opens new window)将八百多个 job 全部基于 Jenkins Pipeline 实现,极大简化了项目配置与维护工作,自此之后再没有什么发布上面的难题。
当时宿主机发布的实现,全部基于参数化构建的特性处理集群里的 IP 列表(事实上在这之后,二丫 (opens new window)增减项目也就只是针对这个字段的调整了),结合 ansible 进行发布,现在随着各种基建的完善,打算改进一版,直接对接 CMDB 获取应用的接口拿到应用对应的主机列表来完成发布的实践,从而完成发布平台这最后一点工作量的覆盖,实现全通用,全自动,围绕以 CMDB 为中心的运维基建工作。
开始正题之前,先看一眼之前已经运行半年左右的实践:
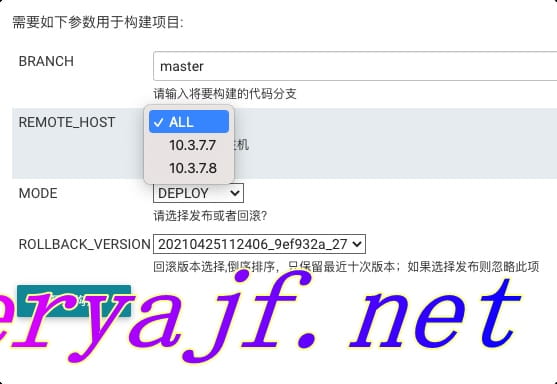
这几个参数满足了二丫 (opens new window)在宿主机发布应用的需求,二丫 (opens new window)基于共享库抽取出 Jenkinsfile 引导文件,又从 Jenkinsfile 里抽取出这四个变量,几个都是常规的变量,作用也显而易见,因此不做过多介绍。实现它们的伪代码(实际应用中需要将如下代码中的部分变量进行提取)如下:
parameters {
string(name: 'BRANCH', defaultValue: 'master', description: '请输入将要构建的代码分支')
choice(name: 'REMOTE_HOST', choices: 'ALL\n10.3.7.7\n10.3.7.8', description: '请选择发布主机,默认ALL')
choice(name: 'MODE', choices: ['DEPLOY','ROLLBACK'], description: '请选择发布或者回滚?')
extendedChoice(description: '回滚版本选择,倒序排序,只保留最近十次版本;如果选择发布则忽略此项', multiSelectDelimiter: ',', name: 'ROLLBACK_VERSION', propertyFile: env.JOB_BASE_NAME, propertyKey: env.JOB_BASE_NAME, quoteValue: false, saveJSONParameterToFile: false, type: 'PT_SINGLE_SELECT', visibleItemCount: 10)
}
2
3
4
5
6
单说 REMOTE_HOST,当二丫 (opens new window)把choices: 'ALL\n10.3.7.7\n10.3.7.8'提取成一个参数,那么每个项目的不同主机就可以通过参数传递,然后利用如下代码渲染出 ansible 需要的主机发布列表:
stage('定义部署主机列表'){
steps{
script{
try{
sh '''
OLD=${IFS}
IFS='\n'
if [ $REMOTE_HOST == "ALL" ];then
echo "[remote]" > ${ANSIBLE_HOSTS}
for i in ${HOSTS};do echo "$i ansible_port=22" >> ${ANSIBLE_HOSTS};done
sed -i '/ALL/d' ${ANSIBLE_HOSTS}
else
echo "[remote]" > ${ANSIBLE_HOSTS}
echo "$REMOTE_HOST ansible_port=34222" >> ${ANSIBLE_HOSTS}
fi
IFS=${OLD}
'''
}catch(exc) {
env.Reason = "定义主机列表出错"
throw(exc)
}
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
那么,现如今想要对接 CMDB 发布服务,则只需要解决两个事情即可:
- 参数化构建处通过 CMDB 接口展示主机列表。
- 定义部署主机列表步骤改造成通过接口获取的方式渲染。
# 2,参数
当二丫 (opens new window)有了明确的目标以及大概的思路之后,凭借着以往网上冲浪时大概看到过有人通过 groovy 实现通过接口渲染参数的模糊印象,开始了漫长地研究之路。
本文如下代码可能需要你根据报错情况添加插件,具体情况具体分析,这里不多赘述。目前简单记得至少需要如下插件:
- Active Choices Plugin (opens new window):支持灵活定义的参数化插件。
- http request plugin (opens new window):支持创建 http 请求的插件。
- Pipeline Utility Steps (opens new window):提供 pipeline 流水线中一些读写文件之类的操作。
找到以往模糊印象中的文章,确定了这里需要使用Active Choices Plugin,通过一些检索,很快确定了基本的发起 http request 的代码,后边一直困住自己的,是在这个步骤获取项目名字的需求,二丫 (opens new window)需要与 CMDB 一起约定一个东西作为项目的唯一 key,不用说,直接用项目名一定是最好的,这个项目名从 gitlab 仓库中的命名,到 Jenkins 中 job 的命名,到 CMDB 中应用的命名,乃至整个生命周期中,都应该是一致的,唯一的。
接下来直接上干货。
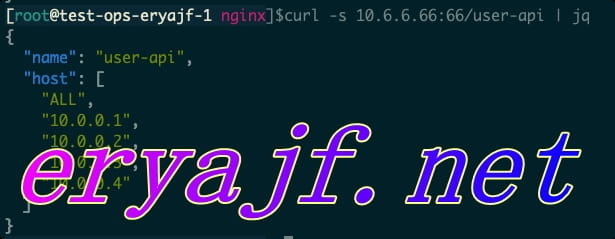
为了模仿 CMDB 接口返回应用对应的数据信息,二丫 (opens new window)这里直接在 Nginx 中添加如下配置:
location /user-api {
default_type application/json;
return 200 '{"name":"user-api","host":["ALL","10.0.0.1","10.0.0.2","10.0.0.3","10.0.0.4"]}';
}
2
3
4
当二丫 (opens new window)请求服务对应的 /user-api 接口时,将会拿到应用对应的集群主机 IP 列表:
然后在 Jenkins 中,创建一个名叫 user-api 的流水线项目,流水线代码如下:
properties([
parameters([
[$class: 'ChoiceParameter', filterLength: 1, filterable: true, randomName: 'choice-parameter-18463792817640626',
name: 'HOST', choiceType: 'PT_SINGLE_SELECT', description: '选择要部署的主机',
script:[
$class: 'GroovyScript',
fallbackScript: [classpath: [], sandbox: false, script: 'return[\'error\']'],
script: [ classpath: [], sandbox: false,
script:'''import hudson.model.*
import groovy.json.JsonSlurperClassic
def getHostList(jobName) {
def url = new URL("http://10.6.6.66:66/${jobName}")
def parsedJSON = parseJSON(url.getText())
return parsedJSON.host
}
def parseJSON(json) {
return new groovy.json.JsonSlurperClassic().parseText(json)
}
return getHostList(Thread.currentThread().toString().split('job')[-1].replace('/',''))
''']]]])])
pipeline{
agent any
stages{
stage('Example'){
steps{
script{
sh """echo ${env.HOST}"""
}
}
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
关于 active choice 插件的流水线语法,这里不多介绍,可参考官方文档,也可在你的 Jenkins 流水线语法中自行生成理解。
说明:
因为 Jenkins 官方对流水线支持的参数化定义仅支持:booleanParam,choice,text,password,file 等几种常用参数,并不支持 active choice 这类复杂的选项定义,因此这里借助
properties的方法来实例化任一需要的对象,同样,该用法可以在 Jenkins 中的流水线语法参考详细了解。示例如下:
使用代码定义 active choice 参数时需要注意一个坑是:如果你在一个项目中定义多个 active choice 参数,那么请确保不同参数的
randomName是唯一的,否则可能会无法正常使用。接着进入到 groovy 脚本区域,在写这里的代码时,参考网络上的写法各种各样,先说引包问题。
同一个方法,有人导包有人不导,后来查了下这块儿:Groovy 提供一些默认的导入。Groovy 默认导入的包有参考 (opens new window):
import java.lang.* import java.util.* import java.io.* import java.net.* import groovy.lang.* import groovy.util.* import java.math.BigInteger import java.math.BigDecimal1
2
3
4
5
6
7
8但二丫 (opens new window)上边的
import groovy.json.JsonSlurperClassic也可以省略。接着是借助 URL 模块儿,传递唯一参数应用名,拿到数据,return 出来,当然这里如果用于生产,还应该再好好设计一下,这里暂时按下不表,在后文再详述。
最后困难的是如果在这个阶段拿到项目名,成了困住二丫 (opens new window)的一个地方,二丫 (opens new window)找遍了网上的资料,试了又试,败了又败,人家说:文章不厌百回改,二丫 (opens new window)说,code 不厌百回试。虽然在 active choice 官方文档处有说明提供了两个变量获取 Jenkins 构建的系统信息:
也见到有人使用这两个变量来获取的,如下:
import hudson.model.* def jobName = this.binding.jenkinsProject.name1
2但经自己的测试,却始终都没拿到。最后还是在 Stack Overflow 中看到一个答案:
def jobName = (Thread.currentThread().toString() =~ /job\/(.*?)\//)[0][1]1如果你所有项目都是单层目录的场景,则用上边的方案没有问题,只不过需要注意的是转义符会报语法错误,可多加一层转义处理:
def jobName = (Thread.currentThread().toString() =~ /job\\/(.*?)\\//)[0][1]1不过因为二丫 (opens new window)测试场景是多目录的情况,发现如上方法拿多层级 job 的时候会有问题,因此个人改造此方法如下:
def jobName = Thread.currentThread().toString().split('job')[-1].replace('/','')1
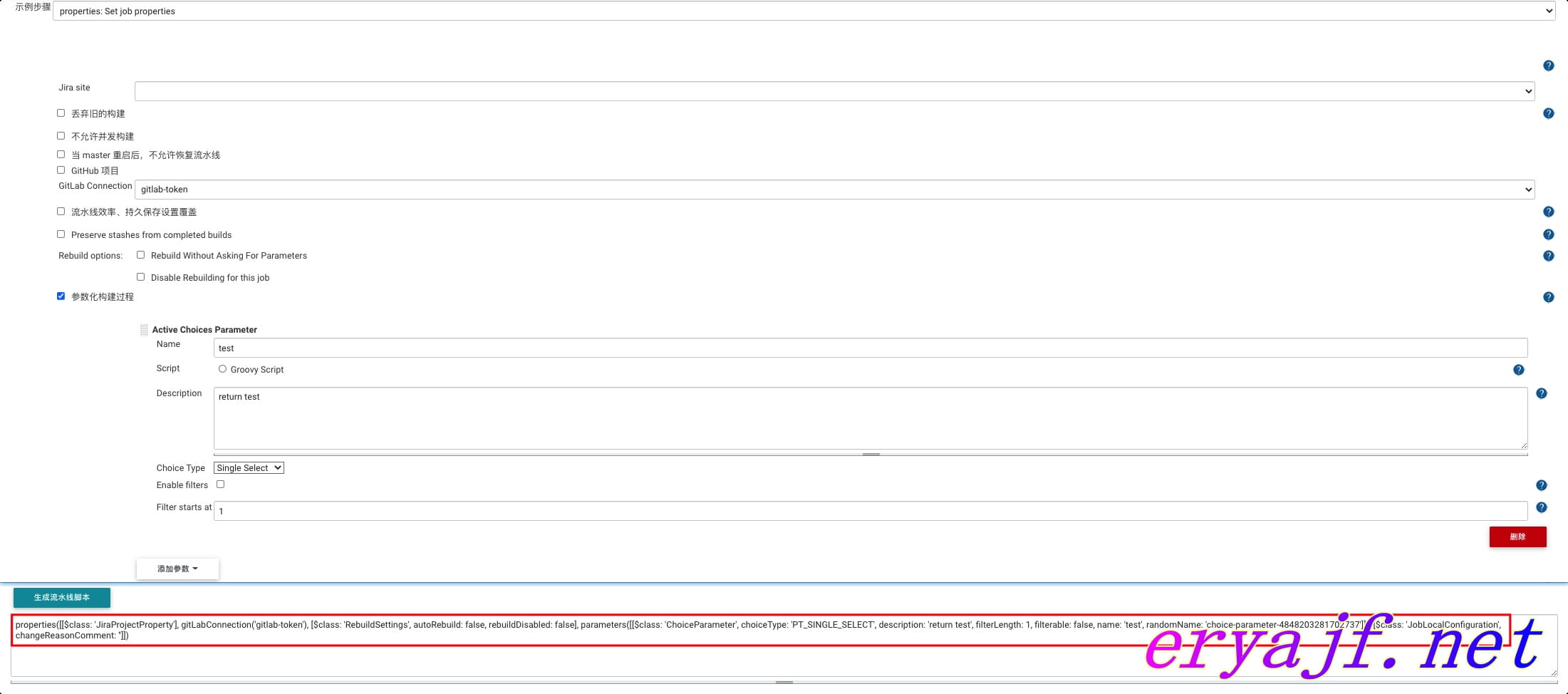

现在来到 Jenkins 当中,在任意目录中创建个项目,命名为 user-api,然后将 Jenkinsfile 文件丢进去,运行一下,发现能够满足需求:

到这里,参数基于 CMDB 接口实时拿主机列表的需求已经满足,接下来就是实现通过接口将数据解析下来的功能了。
# 3,渲染列表
渲染列表也是这次改造工作的重中之重,一开始考虑用 shell 实现,但是觉得接口拿到的 json 经由 shell 处理实在不理想,于是打算用 go 做个脚本,但是丢个 go 的二进制放在流水线中,又违背了操作指令应当显式呈现在定义流程的 code 这一理念,于是暂时放弃 go 的实现方案,打算转用与流水线更亲和的 groovy 来实现这个需求,不必觉得难,事实上在实现如下需求之前,二丫 (opens new window)对 groovy 的编程经验也是零,因此如下的代码实现也会以运维视角来实现,而非纯编程方式,对于将发布流水线写的像编程一个项目那样,二丫 (opens new window)并不喜欢。
但在这里先说一个二丫 (opens new window)后来才知道的事情:在声明式的流水线中,一些场景中对原生的 groovy 代码会有各种各样的奇怪限制,比如二丫 (opens new window)在实验的过程中就遇到过不让用 URL 模块儿,不让用 write 模块儿的,大概报错日志如下:
Scripts not permitted to use staticMethod org.codehaus.groovy.runtime.DefaultGroovyMethods getText java.net.URL
如下:
Method definition not expected here. Please define the method at an appropriate place or perhaps try using a block/Closure instead
后来才了解到,针对 groovy 原生语法的一些常见用法,事实上 Jenkins pipeline 语法中已经提供了相对应的方法进行支持,比如原生的url方法,在 pipeline 中,应该改用 httpRequest方法,原生的json解析方法,可以改用 readJSON方法,原生的 writer.writeLine方法,可以改用 writeFile方法,凡此种种,不一而足。
所以当二丫 (opens new window)用原生 groovy 在本地调试成功之后,屁颠屁颠跑到 Jenkins 上运行时,发现各个步骤都会卡自己一道,最后不得不用 Jenkins 给定的方法进行了重构改造,不过这里还是放一下 groovy 原生的处理方式,仅当留念自己奋斗的成果:
import groovy.json.JsonSlurperClassic
def getHostList(jobName) {
def url = new URL("http://10.6.6.66:66/${jobName}")
def parsedJSON = parseJSON(url.getText())
return parsedJSON.host
}
def parseJSON(json) {
return new groovy.json.JsonSlurperClassic().parseText(json)
}
def newFile = new File(${ANSIBLE_HOSTS})
if (!newFile.exists()) {
newFile.createNewFile()
} else {
newFile.withWriter('utf-8') { writer ->
writer.writeLine '[remote]'
}
host = getHostList(${env.JOB_BASE_NAME})
host -= "ALL"
host.each{
println(it)
newFile.append(it + " ansible_port=22\n")
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
这段代码在本地直接通过 groovy 解析是没毛病的,放到 Jenkins 中就不行了。
于是再次借助 Jenkins 中流水线语法参考,对各个功能点逐个击破,最后完成脚本内容如下:
properties([
parameters([
[$class: 'ChoiceParameter', filterLength: 1, filterable: true, randomName: 'choice-parameter-18463792817640626',
name: 'HOST', choiceType: 'PT_SINGLE_SELECT', description: '选择要部署的主机',
script:[
$class: 'GroovyScript',
fallbackScript: [classpath: [], sandbox: false, script: 'return[\'error\']'],
script: [ classpath: [], sandbox: false,
script:'''import hudson.model.*
def getHostList(jobName) {
def url = new URL("http://10.6.6.66:66/${jobName}")
def parsedJSON = parseJSON(url.getText())
return parsedJSON.host
}
def parseJSON(json) {
return new groovy.json.JsonSlurperClassic().parseText(json)
}
return getHostList(Thread.currentThread().toString().split('job')[-1].replace('/',''))
''']]]])])
pipeline{
agent any
environment {
ANSIBLE_PORT="22" // 定义远程主机ssh端口,一般不需要更改
ANSIBLE_USER="root" // 定义远程主机ssh用户,一般不需要更改
// 定义主机hosts文件,一般不用更改
ANSIBLE_HOSTS="${WORKSPACE}/${env.JOB_BASE_NAME}_hosts"
}
stages{
stage('定义主机列表'){
steps{
script{
try {
if (HOST == 'ALL') {
def response = httpRequest \
httpMode: "GET",
ignoreSslErrors: true,
contentType: 'APPLICATION_JSON',
validResponseCodes: '200',
// requestBody: groovy.json.JsonOutput.toJson(["k1":"v1","k2":"v2"]),
url: "http://10.6.6.66:66/${env.JOB_BASE_NAME}"
println response.content
def props = readJSON text: response.content
props.host -= "ALL"
writeFile file: env.ANSIBLE_HOSTS, text: '[remote]\n'
props.host.each{
appendFile(env.ANSIBLE_HOSTS,it + " ansible_port=${env.ANSIBLE_PORT} ansible_user=${env.ANSIBLE_USER}")
}
} else {
writeFile file: env.ANSIBLE_HOSTS, text: '[remote]\n'
appendFile(env.ANSIBLE_HOSTS,HOST + " ansible_port=${env.ANSIBLE_PORT} ansible_user=${env.ANSIBLE_USER}")
}
}catch(exc) {
env.REASON = "定义主机列表出错"
throw(exc)
}
}
}
}
}
}
// 该方法实现了往文件内追加内容的功能
def appendFile(String fileFullPath, String line) {
if (fileExists(fileFullPath)) {
current = readFile fileFullPath
}
writeFile file: fileFullPath, text: current + line + "\n"
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
说明:这里不一一介绍代码了,捡一些干货聊聊,有话则长,无话则短。
httpRequest在流水线语法中有非常详细的设置项,感兴趣的同学可以去了解查看,这里特地预留了 requestBody,是为了二丫 (opens new window)通过该参数与 CMDB 交互时,能够提供更加灵活的方式,从而让代码更具普适性。readJSON的用法非常简单,让二丫 (opens new window)能够直接解析 json 串。-=是 groovy 语法的一种,能够直接删除掉列表中二丫 (opens new window)不需要的元素。.each是一个遍历方法,它会返回一个 it 对象表示 value。writeFile方法默认是覆盖式写文件,通过一个外挂方法,实现追加功能。
# 4,归纳
经过以上思路的实现之后,二丫 (opens new window)可以来做一些归纳,将一些规范化的东西约定出来,以便于通过同样的配置代码,完成不同的项目发布需求。
唯一 key 串联
CMDB 平台建设期间,应用的模型至少应该有如下定义:
# http://10.6.6.66:66/project?project=test-user-api-runner&env=test ProjectName 全局唯一 ProjectEnv 应用要有环境的属性 test pre prod HostList 主机列表,其中主机列表应该通过请求参数进行区分1
2
3
4
5
6
7
8唯一 key 保障了全局交互的统一,环境标识为应用的不同环境提供不同数据,在 Jenkins 配置发布时,就会有如下三种环境:
test-user-api,pre-user-api,prod-user-api。然后将 job 名字拆分,构造如下请求:A = 'test-user-api-runner' def B = A.tokenize('-') def projectEnv = B[0] println projectEnv B.remove(0) def projectName = B.join('-') println projectName1
2
3
4
5
6
7通过一些处理从 Jenkins 项目名中拿到环境以及项目名的参数,实现一套代码,发布多套环境的需求。
保留冗余字段
除了上边提到的三种环境字段,还应该结合自己的实际保留一定的冗余字段,比如因为经常搞活动而需要扩缩容,这个时候就应该再多个场景
expand-user-api,自动扩容过程中,通过运维平台购买下来的主机通过这个字段返回,然后复制一个项目将代码同步到扩容的主机上去。提高 CMDB 稳定性
当 CMDB 的应用接口暴漏给发布接入之后,同时对 CMDB 所在服务的稳定性提高了要求,原来通过单台提供服务的,现在就需要配置成两台高可用起来。
以 CMDB 为中心
这一举措彻底将发布中心从原来的手动维护转到以 CMDB 为中心的方案中来,那么如果保障 CMDB 中的数据可持续性稳定,准确,就是需要从购买机器,扩缩容流程,等逐个变动的场景中来细细规划。
封装一层
如上策略全局推广之后,所有应用的信息全部维护在 CMDB 中,那么发布就只是一个透明的管道,只需要将应用的参数传递给管道即可触发构建,这个时候,就是适合在 Jenkins 上封装一层,完全集成到运维平台的时候了。有很多公司一上来就要给 Jenkins 封装,最后发现要么无法封装成熟,要么就封装出了个新的 Jenkins。
本文从想法的萌发,到思路的梳理,到逐步的实现,都做了详细介绍以及过程中的心理描写,运维标准化规范化建设之路非常漫长,需要不断地深耕建设,更需要无数这样的点汇聚起来,从而才能形成一片堂堂汪洋。
本文研究完毕之后,我曾在朋友圈发表感慨一段,也摘录与此:
《技术的乐趣》
你在冲破一个新知识点的过程中,难道不充满曲折,困厄,迷惘,反复么!
你知道自己将要达到何方
你知道自己将要面对多少凶险
你几乎靠近最终答案
你经常与正确答案擦肩
你在被自己的怯弱劝退
你在被自己的勇气鼓励
你终于,会收获那最终的正确答案
而这个答案,足够你开心灿烂好久好久
同时摘录了南宋诗人杨万里的一首诗表意:
《桂源铺》- 杨万里
万山不许一溪奔,
拦得溪声日夜喧。
到得前头山脚尽,
堂堂溪水出前村。
# 5,参考
- How to get the job name on a groovy dynamic parameter? (opens new window)
- A real example of Jenkins active choices and reactive parameter (opens new window)
- 实战 Groovy: for each 剖析 (opens new window)
- 在 Java / Groovy 中将数组转换为字符串 (opens new window)
- 如何将文本追加到 jenkinsfile 中的文件 (opens new window)
- Jenkins Pipeline 实现 http 请求并解析响应 (opens new window)
- Groovy: Method definition not expected here (opens new window)
- 文件操作 (opens new window)
- Groovy 教程 (opens new window)
# 6,补充
# 1,参数优化
上边举例中,应用返回的主机列表里还有一个 ALL 字段,这是应用对应的主机列表所不存在的值,通常应用应该只返回主机列表,所以下边对此处做了简单的改造,利用列表的plus参数,将 ALL 字段添加上去。
properties([
parameters([
[$class: 'ChoiceParameter', filterLength: 1, filterable: true, randomName: 'choice-parameter-18463792817640626',
name: 'HOST', choiceType: 'PT_SINGLE_SELECT', description: '选择要部署的主机',
script:[
$class: 'GroovyScript',
fallbackScript: [classpath: [], sandbox: false, script: 'return[\'error\']'],
script: [ classpath: [], sandbox: false,
script:'''import hudson.model.*
def getHostList(jobName,jobEnv) {
def url = new URL("http://10.6.6.66:66/${jobName}/${jobEnv}?token=abcdefg")
def parsedJSON = parseJSON(url.getText())
return parsedJSON.host
}
def parseJSON(json) {
return new groovy.json.JsonSlurperClassic().parseText(json)
}
def getProjetName(name) {
def B = name.tokenize('-')
B.remove(0)
return B.join('-')
}
def jobName = Thread.currentThread().toString().split('job')[-1].replace('/','')
def htmp = ["ALL"]
return htmp.plus(getHostList(getProjetName(jobName),jobName.tokenize('-')[0]))
''']]]])])
pipeline{
agent any
environment {
// 定义主机hosts文件,一般不用更改
ANSIBLE_HOSTS="${WORKSPACE}/${env.JOB_BASE_NAME}_hosts"
}
stages{
stage('初始化主机列表'){
steps{
script{
println env.HOST
}
}
}
}
}
// 该方法实现了往文件内追加内容的功能
def appendFile(String fileFullPath, String line) {
if (fileExists(fileFullPath)) {
current = readFile fileFullPath
}
writeFile file: fileFullPath, text: current + line + "\n"
}
def getProjetName(String name) {
def B = name.tokenize('-')
B.remove(0)
return B.join('-')
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58


 |
|