 Jenkinsfile声明式语法详解
Jenkinsfile声明式语法详解
上篇文章对 Jenkins pipeline 入门做了简单介绍,简单见识了 Jenkinsfile 当中的几个常用的语法关键字,本文将针对声明式的语法进行详细解读,这种解读将会是手册性质的,会有讲解,必要的也会有简单实验演示,但是并不会做完整项目流程的介绍。
手册性质的整理,是为了方便以后用起来之后,查询方便。我个人也常常因为遇到一些陌生的参数,或者不熟悉的用法,到网上各种找,检索到的结果往往也都不十分满意,因此这篇文章,会尽量详细记录各个指令的参数项。
# 1,框架介绍。
一个常规的声明式 Jenkinsfile,一般情况下,有如下常规框架,这个框架基本上每个环节都是必不可少的,所以我就从外到内,先从整体框架讲起。图示如下:
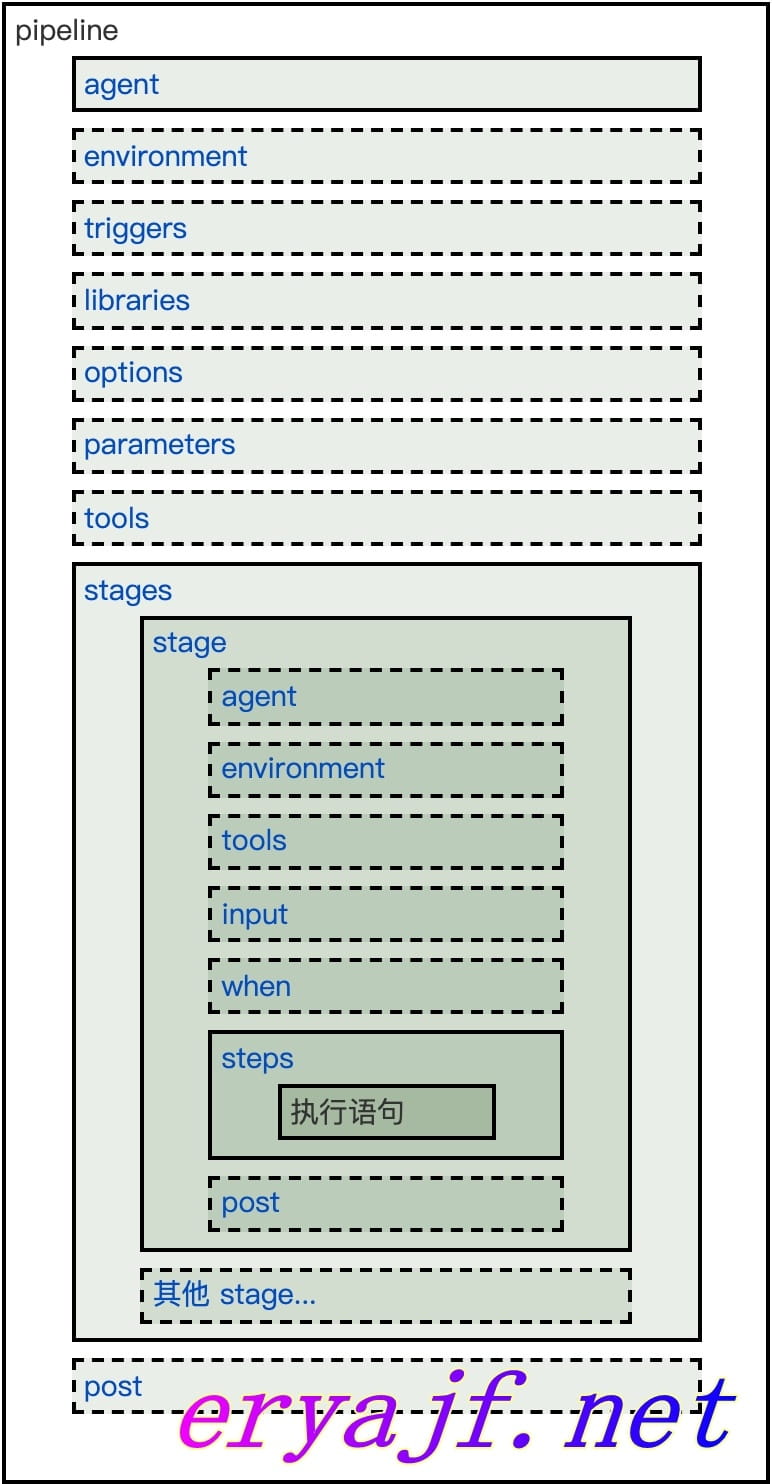
而当我们在 vscode 当中安装了 Jenkins pipeline 插件的之后,输入 pipe 然后回车,默认自动补全出来的内容如下:
pipeline{
agent{
label "node"
}
stages{
stage("A"){
steps{
echo "========executing A========"
}
post{
always{
echo "========always========"
}
success{
echo "========A executed successfully========"
}
failure{
echo "========A execution failed========"
}
}
}
}
post{
always{
echo "========always========"
}
success{
echo "========pipeline executed successfully ========"
}
failure{
echo "========pipeline execution failed========"
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
现在就基于这个基础框架,介绍一下各个组件,因为这些在上篇文章基本上都介绍过,所以略人所详地进行一下讲解。
# 1,pipeline。
用于声明表示流水线的标识,表示这里将采用声明式的语法风格。并不包含什么特殊意义。
# 2,agent。
此关键字用于表示当前流水线将要执行的位置,当我们的 Jenkins 是主从那种集群的时候,可以通过 agent 进行指定,同时也可以基于 docker 容器的构建,因为现在一切都是容器化的时代,所以这里就基于容器的这种方式稍微展开讲一下,介绍一下用法,以后可能会专门用一篇文章展开详解一下妙用。
# 1,常规用法。
日常构建部署中,常常会用到编译工作,因此这里的步骤可以放入到镜像中执行,这里利用 node 项目的编译举一个示例:
pipeline {
agent {
docker {
lable 'docker'
image 'registry.cn-hangzhou.aliyuncs.com/eryajf/node:11.15'
}
}
stages {
stage('Build') {
steps {
sh 'npm install --registry=https://registry.npm.taobao.org'
}
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
当流水线执行的时候,Jenkins 会首先将代码更新,然后将 $WORKSPACE 挂载到容器之中,这个可以通过构建日志中看出来:
docker run -t -d -u 0:0 -w /root/.jenkins/workspace/test-pinpeline -v /root/.jenkins/workspace/test-pinpeline:/root/.jenkins/workspace/test-pinpeline:rw,z -v /root/.jenkins/workspace/test-pinpeline@tmp:/root/.jenkins/workspace/test-pinpeline@tmp:rw,z -e ******** registry.cn-hangzhou.aliyuncs.com/eryajf/node:11.15
接着执行我们定义的 install 编译命令,当然,下边可以继续添加步骤,将代码 rsync 到远程主机,或者其他操作。
此处可用的参数如下:
- lable(可选):定义一个标签,用处不十分大。
- image:定义构建时使用的镜像。
- args:可以定义类似 docker run 命令时的一些参数。
- alwaysPull:布尔类型,是否在每次运行的时候重新拉取镜像。
# 2,添加参数。
日常编译比较影响构建时间的一个因素是本地缓存,因此还可以用如下方式将本地缓存挂载到容器之中,从而加快构建速度。
pipeline {
agent {
docker {
image 'registry.cn-hangzhou.aliyuncs.com/eryajf/node:11.15'
args '-v /root/.npm:/root/.npm'
}
}
stages {
stage('Build') {
steps {
sh 'npm install --registry=https://registry.npm.taobao.org'
}
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
# 3,多个容器。
基于如上的事实,发散我们的思维,我们可以将许多个基础性的步骤,封装成一个又一个镜像,然后在每个步骤中只需调用封装好的镜像,传入所需的参数,即可完成比较复杂的构建。
多个容器用法,如下简示:
pipeline {
agent none
stages {
stage('Build') {
agent {
docker {
image 'registry.cn-hangzhou.aliyuncs.com/eryajf/node:11.15'
args '-v /root/.npm:/root/.npm'
}
}
steps {
sh 'npm install --registry=https://registry.npm.taobao.org'
}
}
stage('deploy'){
agent {
docker {
image 'registry.cn-hangzhou.aliyuncs.com/mckj/ansible'
}
}
steps {
sh 'echo "通过ansbile进行部署"'
}
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
因为 Jenkins 默认会将$WORKSPACE挂载到两个容器中,因此各种操作直接基于当前目录即可,这是值得注意的一点。
这里只是做一个演示,提供一种思路,以后有需要,可以借此发挥更多的妙用。
# 4,基于 Dockerfile。
这种方式,应用的大概比较少,仅做简单介绍。
首先在项目根目录创建一个 Dockerfile:
FROM eryajf/centos:7.5
MAINTAINER eryajf <Linuxlql@163.com>
# Install node
ADD node-v11.15.0-linux-x64.tar.xz /usr/local/
ENV NODE /usr/local/node-v11.15.0-linux-x64
ENV PATH $PATH:$NODE/bin
RUN npm i -g pm2 gulp yarn --registry=https://registry.npm.taobao.org
2
3
4
5
6
7
8
9
10
然后定义 Jenkinsfile:
pipeline {
agent { dockerfile true }
stages {
stage('Build') {
steps {
sh 'npm install --registry=https://registry.npm.taobao.org'
}
}
}
}
2
3
4
5
6
7
8
9
10
感觉起来,这种方式引入了过多的不确定因素,对于构建稳定性,反而不是一件好事儿,所以不太推荐。
# 3,environment
用于设置环境变量,以便于代码复用的时候,更加清晰明了的简化工作内容,只要项目是类似的,那么直接在 environment区域进行配置即可,而无需穿梭到复杂的内容里更改配置。需要注意的一点是,变量的声明可以在 pipeline 以及 stage 区域当中,与大多数语言一样,不同的区域作用域也是不一样的。
# 4,stages
此关键字用于表示流水线各个步骤的声明,其下一层级是 stage,stages 部分至少包含一个 stage。
# 5,stage
表示实际构建的阶段,每个阶段做不同的事情,可按如上方式定义阶段的名称。
# 6,steps
标识阶段之中具体的构建步骤,至少包含一个步骤,在 stage 中有且只能有一个 steps。
# 2,主要参数。
# 1,options
用来配置 Jenkins 应用自身的一些配置项,常用的参数有如下,可根据自己的需求进行选用。
buildDiscarder
保存最近历史构建记录的数量,比较熟悉 Jenkins 的童鞋应该明白这个参数的意义,可以有效控制 Jenkins 主机存储空间。
options { // 表示保留10次构建历史 buildDiscarder(logRotator(numToKeepStr: '10')) }1
2
3
4disableConcurrentBuilds
不允许同时执行流水线,被用来防止同时访问共享资源等。
options { disableConcurrentBuilds() }1
2
3timeout
设置项目构建超时时间,很明显,如果超时,将会以失败状态结束构建。
options { // 设置流水线运行的超过10分钟,Jenkins将中止流水线 timeout(time: 10, unit: 'MINUTES') }1
2
3
4同理还有小时(HOURS)和秒(SECONDS),可根据实际项目需求进行定义。
timestamps
设置在项目打印日志时带上对应时间。
options { // 输出构建的时间信息 timestamps() }1
2
3
4skipDefaultCheckout
在
agent指令中,跳过从源代码控制中检出代码的默认情况。options { // 跳过默认的代码检出 skipDefaultCheckout() }1
2
3
4checkoutToSubdirectory
指定代码检出到
$WORKSPACE的子目录。options { checkoutToSubdirectory('testdir') }1
2
3retry
在构建失败的时候,重新尝试整个流水线的指定次数。
options { retry(3) }1
2
3
常用汇总:
options {
timestamps()
disableConcurrentBuilds()
timeout(time: 10, unit: 'MINUTES')
buildDiscarder(logRotator(numToKeepStr: '10'))
}
2
3
4
5
6
# 2,post
用于定义在整个流水线执行结果的情况,通常可配合通知进行对项目构建状态的告知。有如下几种状态:
always无论流水线或阶段的完成状态如何,都允许在
post部分运行该步骤。changed只有当前流水线或阶段的完成状态与它之前的运行不同时,才允许在
post部分运行该步骤。failure只有当前流水线或阶段的完成状态为"failure",才允许在
post部分运行该步骤, 通常 web UI 是红色。success只有当前流水线或阶段的完成状态为"success",才允许在
post部分运行该步骤, 通常 web UI 是蓝色或绿色。unstable只有当前流水线或阶段的完成状态为"unstable",才允许在
post部分运行该步骤, 通常由于测试失败,代码违规等造成。通常 web UI 是黄色。aborted只有当前流水线或阶段的完成状态为"aborted",才允许在
post部分运行该步骤, 通常由于流水线被手动的 aborted。通常 web UI 是灰色。cleanup总是在最后执行的一个步骤,你可以选择在此步骤进行工作空间的清理工作。详见 (opens new window)
关于这里,可以有比较巧妙的用法,后续可能也会专门列一篇文章来书写。
# 3,tools
定义部署流程中常用的一些工具,这些工具在管理Jenkins--->Global Tool Configuration中添加,然后在项目中引用。
pipeline {
agent any
tools {
maven 'maven'
}
stages {
stage('Example') {
steps {
sh 'mvn --version'
}
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
# 4,parameters
parameters 指令提供用户在触发 Pipeline 时应提供的参数列表,也就是在以往的 free style 风格中最常用到的参数化构建,我们不必在每次新建项目之后,一步一步在 web 界面中配置需要的参数,而是可以直接通过声明式进行参数化风格定义,这样极大简化了配置工作。
parameters 指令支持以下几种常用类型:
string,字符串类型。
以往常常通过这个参数,来定义手动构建时输入将要构建的代码分支,那么这里可以用如下方式表达:
pipeline { agent any parameters { string(name: 'branch', defaultValue: 'master', description: '请输入将要构建的代码分支') } }1
2
3
4
5
6注意:这种声明定义之后,需要手动构建一次,然后配置就会自动落位到原来熟悉的参数化构建中了。choice,选项参数类型。
以往经常会选用这个参数,用于指定构建的方向是部署还是回滚,多个参数有两种表达方式。
其一:pipeline { agent any parameters { choice(name: 'mode', choices: ['deploy', 'rollback'], description: '选择方向!') } }1
2
3
4
5
6其二:pipeline { agent any parameters { choice(name: 'ENV_TYPE', choices: 'test\n\pre\nprod', description: '请选择部署的环境') } }1
2
3
4
5
6
以上两种参数,做一个简单的配置实验,首先准备如下伪代码:
pipeline{
agent any
parameters {
string(name: 'branch', defaultValue: 'master', description: '请输入将要构建的代码分支')
choice(name: 'mode', choices: ['deploy', 'rollback'], description: '选择方向!')
}
stages {
stage('test') {
steps{
script {
sh "java -version"
}
}
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
创建一个新的 pipeline 风格的项目,将如上代码填写进入,点击构建,然后参数就会落位到对应的位置了。
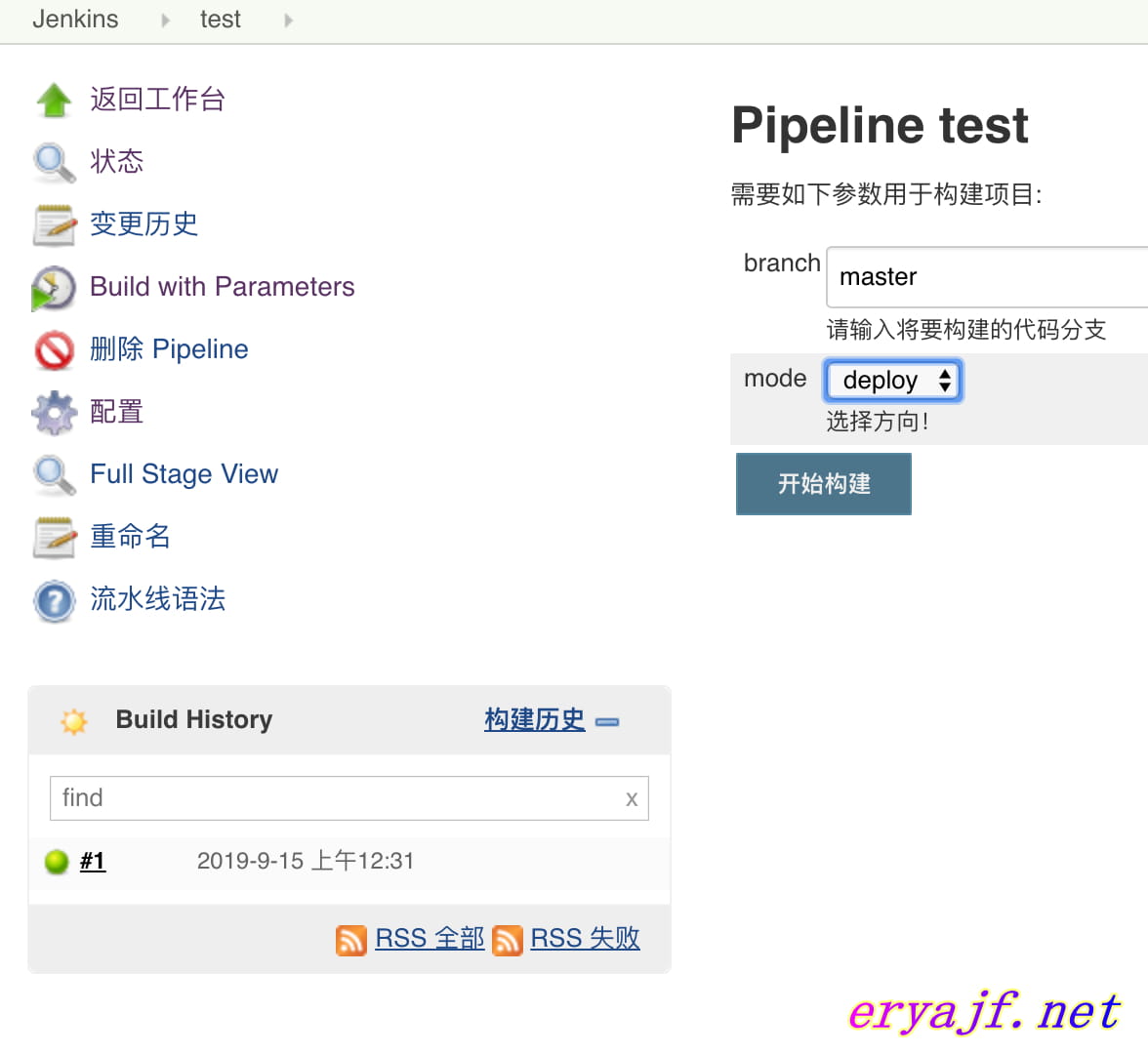
接着继续介绍这里的参数。
booleanParam,布尔值参数
就是定义一个布尔类型参数,用户可以在 Jenkins UI 上选择是还是否,选择是表示代码会执行这部分,如果选择否,会跳过这部分。
pipeline { agent any parameters { booleanParam(name: 'DEBUG_BUILD', defaultValue: true, description: '') } }1
2
3
4
5
6text,文本参数
文本(text)的参数就是支持写很多行的字符串。
pipeline { agent any parameters { text(name: 'Deploy_text', defaultValue: 'One\nTwo\nThree\n', description: '') } }1
2
3
4
5
6password,密码参数
密码(password)参数就是在 Jenkins 参数化构建 UI 提供一个暗文密码输入框,所有需要脱敏的信息,都可以通过这个参数来配置。
Pipeline { agent any parameters { password(name: 'PASSWORD', defaultValue: 'SECRET', description: 'A secret password') } }1
2
3
4
5
6
7
如上参数已经基本上可以满足日常需求,思路大概就是通过 Jenkinsfile 的配置,部署仍旧沿用以往常规的手动部署的方式,这种方式在高效率持续构建方面,似乎已经不大适合,所以以后可以与 input 参数配合使用,这里不展开,以后可专门列一篇文章来讲。
# 5,input
stage 的 input 指令允许你使用 input step (opens new window)提示输入。 在应用了 options 后,进入 stage 的 agent 或评估 when 条件前, stage 将暂停。 如果 input 被批准, stage 将会继续。 作为 input 提交的一部分的任何参数都将在环境中用于其他 stage。
一个成熟的 input,大概需要如下几个要点:
message
- 必需的。 这将在用户提交
input时作为说明信息呈现给用户。
- 必需的。 这将在用户提交
id
input的可选标识符, 默认为stage名称。
ok
- 自定义确定按钮的文本信息。
submitter
- 可选的以逗号分隔的用户列表或允许提交
input的外部组名。默认允许任何用户。
- 可选的以逗号分隔的用户列表或允许提交
submitterParameter
- 环境变量的可选名称。如果存在,用
submitter名称设置。
- 环境变量的可选名称。如果存在,用
parameters
- 提示提交者提供的一个可选的参数列表,结合好了,会有非常多的妙用。
这里简单创建一个项目,用于一种思路的引导:
pipeline{
agent any
environment{
approvalMap = ''
}
stages {
stage('pre deploy'){
steps{
script{
approvalMap = input (
message: '准备发布到哪个环境?',
ok: '确定',
parameters:[
choice(name: 'ENV',choices: 'test\npre\nprod',description: '发布到什么环境?'),
string(name: 'myparam',defaultValue: '',description: '')
],
submitter: 'admin',
submitterParameter: 'APPROVER'
)
}
}
}
stage('deploy'){
steps{
echo "操作者是 ${approvalMap['APPROVER']}"
echo "发布到什么环境 ${approvalMap['ENV']}"
echo "自定义参数 ${approvalMap['myparam']}"
}
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
点击构建,程序将会在 input 的步骤停住,等待用户进行相应输入,从而进行不同构建,当然,这里的多环境只是做了一个简单的打印,如果再结合上判断,以及不同分支构建,就能实现更加丰富的功能,不用着急,很快就会介绍 Jenkinsfile 中的判断了。
注意:开头环境变量,先创建了一个空的名称,后边再将定义的参数结果赋值给开头的变量,这样便于后边调用,调用时直接引用这个 Map 类型即可。另外,因为这种赋值的方式属于 Groovy 语言的赋值方式,因此对应的赋值过程需要放在 script 块中。
# 6,when
when 指令允许流水线根据给定的条件决定是否应该执行阶段。 when 指令必须包含至少一个条件。 如果 when 指令包含多个条件, 所有的子条件必须返回 True,阶段才能执行。
when 指令有一些内置的条件判断关键字,这些关键字用好了,会给生产带来极大的效率提升,接下来就来认识一下这些关键字。
# 1,branch
很明显,这个参数是针对于项目分值来做判断的,在配置多分支构建的场景下,使用会比较方便。比如结合上边 input 的场景,我们定义了一个字符参数,用于区别代码发布的分支与环境,不同的分支部署到不同的环境,原来的思路,大概是用 if-else 判断来实现。
stage('deploy to test'){
steps{
script{
if (env.GIT_BRANCH == 'test'){
echo "deploy to test env"
}
}
}
}
stage('deploy to prod'){
steps{
script{
if (env.GIT_BRANCH == 'master'){
echo "deploy to prod env"
}
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
前边提到过,script 是 Groovy 风格的语法,并不是本文推荐的风格,因此可以用 when 来代替上边的代码:
stage('deploy to test'){
when {
branch 'test'
}
steps{
echo "deploy to test env"
}
}
stage('deploy to prod'){
when {
branch 'master'
}
steps{
echo "deploy to prod env"
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
注意:这里的 branch 语法匹配,还支持通配符类型的,比如,branch 'test.*',表示匹配到以 test 开头的分支。
这种用法更多应用在多分支构建场景中,后边有机会将会专门用一篇文章来介绍。
# 2,environment
同样也是一个判断,只不过判断的参数来源是环境变量的值,如果环境变量的值与我们定义的相同,则执行:
when{
environment name: 'ENV',value: 'prod'
}
2
3
# 3,not
当嵌套条件是错误时,执行这个阶段,必须包含一个条件,例如:
when {
not { branch 'master' }
}
2
3
判断环境条件时,用如下写法:
when {
not { environment name: 'mode',value: 'deploy' }
}
2
3
# 4,allOf
当所有的嵌套条件都正确时,才执行。例如:
when {
allOf {
branch 'master';
environment name: 'DEPLOY_TO', value: 'production'
}
}
2
3
4
5
6
需要注意的是:在 when 判断当中,默认多条件之间的关系为逻辑与,因此多个条件的时候,也可以不写 allOf 标志,可以写成如下:
when {
branch 'master';
environment name: 'DEPLOY_TO', value: 'production'
}
2
3
4
# 5,anyOf
当至少有一个嵌套条件为真时,执行这个阶段,必须包含至少一个条件,例如:
when {
anyOf {
branch 'master';
branch 'dev'
}
}
2
3
4
5
6
# 6,beforeAgent
正常情况下,程序都是自上而下执行的,也就是在 agent 之后才会执行 when,但是某些场景中,可能我们需要先做一下判断,然后再进入到 agent 字段中的,那么这个时候,就需要用到 beforeAgent。
pipeline {
agent none
stages {
stage('Example Build') {
steps {
echo 'Hello World'
}
}
stage('Example Deploy') {
agent {
label "some-label"
}
when {
beforeAgent true
branch 'production'
}
steps {
echo 'Deploying'
}
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
# 7,expression
expression :当指定的 Groovy 表达式求值为 true 时执行阶段。
when {
expression { return params.DEBUG_BUILD }
}
2
3
注意,从表达式返回字符串时,必须将它们转换为布尔值或返回null表示为false。 简单地返回0或false仍将评估为true。
when {
expression { BRANCH_NAME ==~ /(production|staging)/ }
anyOf {
environment name: 'DEPLOY_TO', value: 'production'
environment name: 'DEPLOY_TO', value: 'staging'
}
}
2
3
4
5
6
7
# 8,changelog
如果构建的 SCM 更新日志包含给定的正则表达式模式,则执行该阶段 例如:
when {
changelog '.*^\\[DEPENDENCY\\] .+$'
}
2
3
# 9,changeset
如果构建的 SCM 变更集包含与给定字符串或 glob 匹配的一个或多个文件,则执行该阶段。 例如:
when {
changeset "**/*.js"
}
2
3
默认情况下,路径匹配不区分大小写,可以使用 caseSensitive 参数关闭, 例如:
when {
changeset glob: "ReadMe.*", caseSensitive: true
}
2
3
# 10,equals
当期望值等于实际值时执行阶段, 例如:
when {
equals expected: 2, actual: currentBuild.number
}
2
3
# 11,tag
如果TAG_NAME变量与给定模式匹配,则执行该阶段。例如:
when {
tag "release-*"
}
2
3
如果提供了空模式,则如果TAG_NAME变量存在,则将执行该阶段(与 buildingTag()相同)。
可以在属性之后添加可选参数比较器,以指定如何评估匹配的任何模式:EQUALS用于简单字符串比较(默认值),GLOB用于 ANT 样式路径 glob(与例如变更集相同)或REGEXP用于常规 表达匹配。 例如:
when {
tag pattern: "release-\\d+", comparator: "REGEXP"
}
2
3
# 12,triggeredBy
在给定的参数触发当前构建时执行该阶段。例如:
when { triggeredBy 'SCMTrigger' }
when { triggeredBy 'TimerTrigger' }
when { triggeredBy 'UpstreamCause' }
when { triggeredBy cause: "UserIdCause", detail: "vlinde" }
2
3
4
5
6
7
# 7,triggers
triggers指令用于定义流水线触发的一些机制与条件。常规情况下,我们的项目都是基于手动点击部署,这种策略尤其适用于线上环境,但在测试环境,乃至于预发环境,应该对自动构建有更高的集成度,使开发者只关注于开发,而不必过多纠结构建的过程。
目前流水线支持的触发器有三种:cron, pollSCM 和 upstream。
# 1,cron
采用与 Linux 系统一样的定时任务管理方案,当然也加入了一些更简单的参数项,以应对某些需要定期执行的场景,其实如果发散一下思维,我们完全可以用 cron 这种功能,来作为整个系统的定时任务管理中心,所有主机的定时任务都汇总到这里来,管理起来也方便很多。
pipeline {
agent any
triggers {
cron('* * * * *')
}
stages {
stage('cronjob test') {
steps {
echo '这是一个定期执行的任务'
}
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
定时任务的语法就不展开讲了,只列几个比较特殊的,而且比较有空的。
H关键字,H 亦即 Hash,表示当前位置跨度范围内随机一值。假如我们使用定时任务功能,像我上边提到的,管理了大量的机器,那么如果在同一时间突然批量的机器执行任务,势必会产生负载不均衡的情况,这个时候就可以这样写:
H 02 * * *表示凌晨两点的一个小时中,随机的一个时间点执行任务。同时还可以用一些别名来简化操作。
@yearly:每年执行一次@monthly:每月执行一次@weekly:每周执行一次@daily:每天执行一次@midnight:代表半夜 12 点到凌晨 2:59 之间的某个时间。@hourly:每小时执行一次
# 2,pollSCM
表示定期对代码仓库进行检测,如果有变化,则自动触发构建。我思索再三,没有想到这种策略在实际生产中的应用场景,故此不做过多介绍。
pipeline {
agent any
triggers {
pollSCM('* * * * *')
}
stages {
stage('cronjob test') {
steps {
echo '每分钟检测一次代码仓库的变化'
}
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
# 3,upstream
当 B 项目的执行依赖 A 项目的执行结果是,A 就是 B 的上游项目,在 Jenkins2.22 以上的版本中,可以通过 upstream 关键字进行这种关系的表示。
triggers {
// job1,job2都是任务名称
upstream(upstreamProjects: 'job1,job2', threshold: hudson.model.Result.SUCCESS)
}
2
3
4
hudson.model.Result是一个枚举用于指示上游项目状态,包含以下指令:
- ABORTED:任务被手动终止。
- FAILURE:构建失败。
- SUCCESS:构建成功。
- UNSTABLE:存在一些错误,但不至于构建失败。
- NOT_BUILT:再多阶段构建时,前面阶段的问题导致后面阶段无法执行。
# 4,gitlab 事件触发。
这个才是真正更多应用场景的,大多时候,我们都默认将项目配置为,开发者提交某些分支,然后自动触发对应的构建。传统方式下,需要比较复杂的几步配置,但是在 pipeline 中也可以通过代码形式对这种触发器进行配置,实在是一大便利神器。
到这儿,基本上每个项目在 Jenkins 当中的耦合,我们可以看到,越来越少了,我们运维人员,只需专注维护 Jenkinsfile,然后创建对应项目,只需在流水线处配置代码 url 即可。
这里先简单做一下示例介绍,并不展开,后边也会专门写篇文章来介绍这种应用方式,注意,gitlab 触发 Jenkins 的构建需要依赖Gitlab插件,而并不需要插件当中列出来的所谓的 gitlab hook。
pipeline {
agent any
triggers{
gitlab( triggerOnPush: true,
triggerOnMergeRequest: true,
branchFilterType: 'All',
secretToken: "028d848ab64f")
}
stages {
stage('build') {
steps {
echo '提交触发的构建'
}
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
对于触发器所用到的参数,这里简单介绍一下:
triggerOnPush:当 Gitlab 触发 push 事件时,是否执行构建。
triggerOnMergeRequest:当 Gitlab 触发 mergeRequest 事件时,是否执行构建。
branchFilterType:只有符合条件的分支才会触发构建,必选,否则无法实现触发。
可选参数有:
- All:所有分支。
- NameBasedFilter:基于分支名进行过滤,多个分支名使用逗号分隔。
- includeBranchesSpec:基于 branchFilterType 值,输入期望包括的分支的规则。
- excludeBranchesSpec:基于 branchFilterType 值,输入期望排除的分支的规则。
- RegexBasedFilter:基于正则表达式对分支名进行过滤。
- sourceBranchRegex:定义期望的通过正则表达式限制的分支规则。
所有分支这个选项不用解释了,其余两个选项怎么用,才是比较重要,而且可能在实际生产中,经常或者一定会用到的。但是网上的文章,乃至于 Jenkins 的官方文档,也都只是像上边那样,提到了有这样的语法规则存在,并没有任何一个地方给出示例的,当我去到 Gitlab 插件的官方地址后,发现了下边第一种语法的简单示例,仍旧没有我想要的基于正则限制的那种,于是,各位注意,看到这个地方的,都是缘分,也是福气,因为搜遍全网也没有的示例,首次亮相,就是在这里。
- 如果只接受固定分支的触发请求,语法如下:
triggers{ gitlab( triggerOnPush: true, triggerOnMergeRequest: true, branchFilterType: "NameBasedFilter", includeBranchesSpec: "release", secretToken: "${env.git_token}") }1
2
3
4
5
6
7- 如果想通过正则匹配到某些分支进行触发,语法如下:
triggers{ gitlab( triggerOnPush: true, triggerOnMergeRequest: true, branchFilterType: "RegexBasedFilter", sourceBranchRegex: "test.*", secretToken: "${env.git_token}") }1
2
3
4
5
6
7
注意:所有触发器同样都需要先手动执行一次,让 Jenkins 加载其中的配置,对应的指令才会生效。
# 8,parallel
parallel 关键字用于指定某些阶段可以并行的情况,当然,流水线的情况下,大概率都是串行的场景,也正符合所谓流水管道的定义,这里简单介绍一下并行的用法,并不展开过多讲解。
声明式流水线的阶段可以在他们内部声明多隔嵌套阶段, 它们将并行执行。 注意,一个阶段必须只有一个 steps 或 parallel 的阶段。 嵌套阶段本身不能包含进一步的 parallel 阶段, 但是其他的阶段的行为与任何其他 stage 相同。任何包含 parallel 的阶段不能包含 agent 或 tools 阶段, 因为他们没有相关 steps。
另外, 通过添加 failFast true 到包含 parallel的 stage 中, 当其中一个进程失败时,你可以强制所有的 parallel 阶段都被终止。
pipeline {
agent any
stages {
stage('Non-Parallel Stage') {
steps {
echo 'This stage will be executed first.'
}
}
stage('Parallel Stage') {
failFast true
parallel {
stage('并行一') {
steps {
echo "并行一"
}
}
stage('并行二') {
steps {
echo "并行二"
}
}
stage('并行三') {
stages {
stage('Nested 1') {
steps {
echo "In stage Nested 1 within Branch C"
}
}
stage('Nested 2') {
steps {
echo "In stage Nested 2 within Branch C"
}
}
}
}
}
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
# 3,其他参数
# 1,sh
当我们需要执行系统命令的时候,可以通过此关键字引入。简单示例如下:
stage('部署到测试环境'){
when {
branch 'test'
}
steps{
sh 'rsync -avz --progress -e 'ssh -p 22' --exclude='Jenkinsfile' --exclude='.git' --delete ${WORKSPACE}/ root@$remote_ip:$remote_dir'
}
}
stage('部署到线上环境') {
when {
branch 'master'
}
steps {
sh '''
echo "开始部署"
rsync -avz --progress -e 'ssh -p 22' --exclude='Jenkinsfile' --exclude='.git' --delete ${WORKSPACE}/ root@192.168.3.61:$remote_dir
'''
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
# 2,deleteDir
表示删除当前目录,通常用在构建完毕之后清空工作空间,或者结合 dir 关键字使用。
stage('delete') {
steps {
echo '清理工作目录'
deleteDir()
}
}
2
3
4
5
6
另外还有一个 clean(此方法依赖于插件 Workspace Cleanup)清理工作空间时用法与之类似。
stage('delete') {
steps {
echo '清理工作目录'
cleanWs()
}
}
2
3
4
5
6
区别在于 deleteDir 可以指定目录删除。
# 3,dir。
切换目录,默认流水线工作中工作空间目录中,使用 dir 可以进行目录的切换。
dir("/var/logs"){
deleteDir()
}
2
3
# 4,fileExists
判断文件是否存在。可用绝对路径,也可以使用相对路径,相对路径的时候,记住是基于 $WORKSPACE的。
pipeline {
agent any
environment {
git_url = "git@192.168.3.65:jenkins-learn/hello-world.git"
remote_ip = "192.168.3.67"
remote_dir = "/opt/hello"
}
options {
buildDiscarder(logRotator(numToKeepStr: '10'))
disableConcurrentBuilds()
timestamps()
}
stages {
stage('rsync') {
steps {
script {
build_file = "$WORKSPACE/README.md"
if(fileExists(build_file) == true) {
sh '''
rsync -avz --progress -e 'ssh -p 22' --exclude='Jenkinsfile' --exclude='.git' --delete ${WORKSPACE}/ root@$remote_ip:$remote_dir
'''
}else {
error("here haven't find json file")
}
}
}
}
stage('delete') {
steps {
echo '清理工作目录'
cleanWs()
}
}
}
post {
success {
sh "echo 成功了"
}
failure {
sh "echo 失败了"
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
这个例子比较适合生产当中的情境,部署的步骤放在编译的后边,如果编译之后,Java 项目的 war 包没有生成,那么我们跳出构建,如果生成了,则执行构建的步骤。
# 5,error
主动报错,终止当前流水线。
上边已经引用到了,通常在布尔参数之后会选用。
# 6,timeout
代码块超时时间。通常这在执行一些编译步骤如遇不可知情况导致编译失败而又不退出的情况。
timeout 支持如下参数:
- time:整型,超时时间。
- unit:时间单位,支持的值有 NANOSECONDS,MICROSECONDS,MILLISECONDS,SECONDS,MINUTES(默认),HOURS,DAYS.
- activity:布尔类型,如果为 true,则只有当日志没有活动之后,才真正算超时。
用法,直接在将要执行的阶段之外,用关键字包裹即可:
timeout(20){
steps{
sh 'rsync -avz --progress -e 'ssh -p 22' --exclude='Jenkinsfile' --exclude='.git' --delete ${WORKSPACE}/ root@$remote_ip:$remote_dir'
}
}
2
3
4
5
# 7,waitUtil
等待条件满足,不断重复代码块中的内容,直到条件为 true。这个功能的应用场景我倒是想到了一个,很贴切,有一些服务在生产环境跑着,并不能直接关闭发布,而往往加入一个优雅停机的功能,因此调用停机接口之后,我们就可以做一个等待,等待服务端口彻底关闭之后,再进行部署,当然,最好再配合一下 timeout,以避免死循环。
timeout(10){
waitUntil{
script{
def r = sh script: 'curl http://exmaple',returnStatus: true
return ( r == 0 )
}
}
}
2
3
4
5
6
7
8
# 8,retry
重复执行某个块,如果某次执行中有异常,则跳出当次,而不会影响整体。注意,在执行 retry 过程中,用户无法手动终止流水线。
steps {
retry(5){
script{
sh script: 'curl http://exmaple',returnStatus: true
}
}
}
2
3
4
5
6
7
注意:使用 retry 将执行的内容包住。
# 9,sleep
让 pipeline 睡眠一段时间。
支持参数如下:
- time:整型,休眠时间。
- unit:时间单位,支持的值有 NANOSECONDS,MICROSECONDS,MILLISECONDS,SECONDS(默认),MINUTES,HOURS,DAYS.
sleep(120) //休眠120秒
sleep(time: '2',unit: "MINUTES") //休眠2分钟
2
# 10,try&catch
尽管我非常推崇日常构建采用声明式的即可,但是有一些脚本式中比较不错的参数,也是值得学习,而且值得运用的。这个 try 与 catch 就是类似的一种。
日常流水线构建中,我们希望整条线每一阶段都是正常的,一旦有异常的情况,就应该退出构建。比如我们不应该在编译代码失败的情况下,还去重启服务,部署服务,这样极可能会造成一些不可知的问题,严重的还可能因为构建引发服务问题。
简单说明就是,流水线会顺行执行 try 关键字块内的语句,如果所有语句执行都正常,那么程序正常退出,如果有异常,则 catch 部分将会捕捉错误,进行打印,并退出整个流水线,这一点非常关键,某个阶段有异常,整个构建结束,这一特性,值得推广到所有的流水线当中应用起来。
简单示例:
pipeline{
agent any
stages{
stage('Example1') {
steps {
script {
try {
echo 'aaa'
eccho 'bbb'
echo 'ccc'
} catch (err) {
echo 'err'
}
}
}
}
stage('Example2') {
steps {
script {
try {
echo 'aaa'
echo 'ccc'
} catch (err) {
echo 'err'
}
}
}
}
}
post{
always{
echo "========always========"
}
success{
echo "========pipeline executed successfully ========"
}
failure{
echo "========pipeline execution failed========"
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
将代码放到 pipeline 当中,执行以下,可以看下构建日志:

可以看到,因为阶段 1 中有异常,导致程序退出,阶段 2 也没有执行,并且在最后抛出了异常的内容。
# 11,docker
在流水线中使用 docker,能够方便我们对一些环境进行隔离,以及一些优秀语法的应用使得构建更加优雅。
上边 agent 调用 docker 已经介绍了,这里着重再说明一下打镜像的操作。
# 1,构建容器
为了构建 Docker 镜像,Docker 流水线 (opens new window) 插件也提供了一个 build() 方法用于在流水线运行期间从存储库的Dockerfile 中创建一个新的镜像。
使用语法 docker.build("my-image-name") 的主要好处是, 脚本化的流水线能够使用后续 Docker 流水线调用的返回值, 比如:
node {
checkout scm
def customImage = docker.build("my-image:${env.BUILD_ID}")
customImage.inside {
sh 'make test'
}
}
2
3
4
5
6
7
该返回值也可以用于通过 push() 方法将 Docker 镜像发布到 Docker Hub (opens new window), 或 custom Registry (opens new window),比如:
node {
checkout scm
def customImage = docker.build("my-image:${env.BUILD_ID}")
customImage.push()
}
2
3
4
5
镜像 "tags"的一个常见用法是 为最近的, 验证过的, Docker 镜像的版本,指定 latest 标签。 push() 方法接受可选的 tag 参数, 允许流水线使用不同的标签 push customImage , 比如:
node {
checkout scm
def customImage = docker.build("my-image:${env.BUILD_ID}")
customImage.push()
customImage.push('latest')
}
2
3
4
5
6
7
在默认情况下, build() 方法在当前目录构建一个 Dockerfile。提供一个包含 Dockerfile文件的目录路径作为build() 方法的第二个参数 就可以覆盖该方法, 比如:
node {
checkout scm
def testImage = docker.build("test-image", "./dockerfiles/test")
testImage.inside {
sh 'make test'
}
}
2
3
4
5
6
7
8
从在 ./dockerfiles/test/Dockerfile中发现的 Dockerfile 中构建test-image。
通过添加其他参数到 build() 方法的第二个参数中,传递它们到 docker build (opens new window)。 当使用这种方法传递参数时, 该字符串的最后一个值必须是 Docker 文件的路径。
该示例通过传递 -f标志覆盖了默认的 Dockerfile :
node {
checkout scm
def dockerfile = 'Dockerfile.test'
def customImage = docker.build("my-image:${env.BUILD_ID}", "-f ${dockerfile} ./dockerfiles")
}
2
3
4
5
从在./dockerfiles/Dockerfile.test发现的 Dockerfile 构建 my-image:${env.BUILD_ID}。
# 2,使用自定义注册表
默认情况下, Docker 流水线 (opens new window) 集成了 Docker Hub (opens new window)默认的 Docker 注册表。 .
为了使用自定义 Docker 注册吧, 脚本化流水线的用户能够使用 withRegistry() 方法完成步骤,传入自定义注册表的 URL, 比如:
node {
checkout scm
docker.withRegistry('https://registry.example.com') {
docker.image('my-custom-image').inside {
sh 'make test'
}
}
}
2
3
4
5
6
7
8
9
10
对于需要身份验证的 Docker 注册表, 从 Jenkins 主页添加一个 "Username/Password" 证书项, 并使用证书 ID 作为 withRegistry()的第二个参数:
node {
checkout scm
docker.withRegistry('https://registry.example.com', 'credentials-id') {
def customImage = docker.build("my-image:${env.BUILD_ID}")
/* Push the container to the custom Registry */
customImage.push()
}
}
2
3
4
5
6
7
8
9
10
11
# 3,运行 "sidecar" 容器
在流水线中使用 Docker 可能是运行构建或一组测试的所依赖的服务的有效方法。类似于 sidecar 模式 (opens new window), Docker 流水线可以"在后台"运行一个容器 , 而在另外一个容器中工作。 利用这种 sidecar 方式, 流水线可以为每个流水线运行 提供一个"干净的" 容器。
考虑一个假设的集成测试套件,它依赖于本地 MySQL 数据库来运行。使用 withRun 方法, 在 Docker Pipeline (opens new window) 插件中实现对脚本化流水线的支持, Jenkinsfile 文件可以运行 MySQL 作为 sidecar :
node {
checkout scm
/*
* In order to communicate with the MySQL server, this Pipeline explicitly
* maps the port (`3306`) to a known port on the host machine.
*/
docker.image('mysql:5').withRun('-e "MYSQL_ROOT_PASSWORD=my-secret-pw" -p 3306:3306') { c ->
/* Wait until mysql service is up */
sh 'while ! mysqladmin ping -h0.0.0.0 --silent; do sleep 1; done'
/* Run some tests which require MySQL */
sh 'make check'
}
}
2
3
4
5
6
7
8
9
10
11
12
13
该示例可以更进一步, 同时使用两个容器。 一个 "sidecar" 运行 MySQL, 另一个提供执行环境 (opens new window), 通过使用 Docker 容器链接 (opens new window)。
node {
checkout scm
docker.image('mysql:5').withRun('-e "MYSQL_ROOT_PASSWORD=my-secret-pw"') { c ->
docker.image('mysql:5').inside("--link ${c.id}:db") {
/* Wait until mysql service is up */
sh 'while ! mysqladmin ping -hdb --silent; do sleep 1; done'
}
docker.image('centos:7').inside("--link ${c.id}:db") {
/*
* Run some tests which require MySQL, and assume that it is
* available on the host name `db`
*/
sh 'make check'
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
上面的示例使用 withRun公开的项目, 它通过 id 属性具有可用的运行容器的 ID。使用该容器的 ID, 流水线通过自定义 Docker 参数生成一个到inside() 方法的链。
The id property can also be useful for inspecting logs from a running Docker container before the Pipeline exits:
sh "docker logs ${c.id}"
# 12,withEnv
默认情况下声明的环境变量的生效时间都是贯穿整个流水线声明的,如果想要更改一个变量的值,则可以用 withEnv临时修改,在区块之外即恢复:
pipeline {
agent any
environment {
Name = 'null'
}
stages {
stage('Stage 1'){
steps{
catchError(buildResult: 'UNSTABLE', stageResult: 'FAILURE'){
script {
echo env.Test_Category_Name // 输出 null
withEnv(["Name =Test"]) {
echo env.Test_Category_Name // 输出 Test
}
echo env.Test_Category_Name // 输出 null
}
}
}
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
参考内容:
- Jenkins 官方文档 (opens new window)
- https://blog.csdn.net/u011541946
- Jenkins 2.x 实践指南


 |
|