 实践一次抓包看到TCP的三次握手与四次挥手及其他
实践一次抓包看到TCP的三次握手与四次挥手及其他
# 1,前言
直到现在,我甚至都没有真正地去实际操作过抓包这个事儿,可能对一个运维工作者来说,这是不可想象的,然而事实就是这样。
我从来没打算逃避自己不会抓包这事儿,这一点在同事们经常脱口而出抓 A 抓 B,而我往往都默不作声即可验证。当然,另一方面,我也从来没打算完全放弃学习抓包,当工作内容越往网络与协议等的深入,我就越觉得这是一个不可回避的事情了。
前几天一个同事分享了《wireshark 网络分析的艺术》这本书给我,让我一下子燃起了对抓包以及网络分析的热情,于是就有了这篇文章。
TCP 协议的相关内容非常多非常深,不过面试时三次握手四次挥手则是经常出现的问题,工作中我们在面对以及处理一些 TCP 相关问题时,也都需要用到这些知识,我始终都不敢说自己掌握的多么熟练,今天,借助于第一次抓包的经历,来分享一下 TCP 的三次握手以及四次挥手。
# 2,抓包
通过在主机上使用tcpdump进行抓包,将抓包内容保存到文件中,然后再用wireshark进行分析。
localhost —-> http://eryajf.net/1040.html
以本地作为客户端,然后请求远程网站。
先在本机起一个监听程序:
tcpdump -i ens33 -s 0 -n -S host eryajf.net -w eryajf.cap
然后在本机请求远程主机:
curl http://eryajf.net/1040.html
接着停掉抓包程序,将抓包文件 down 下来,使用 wireshark 打开。
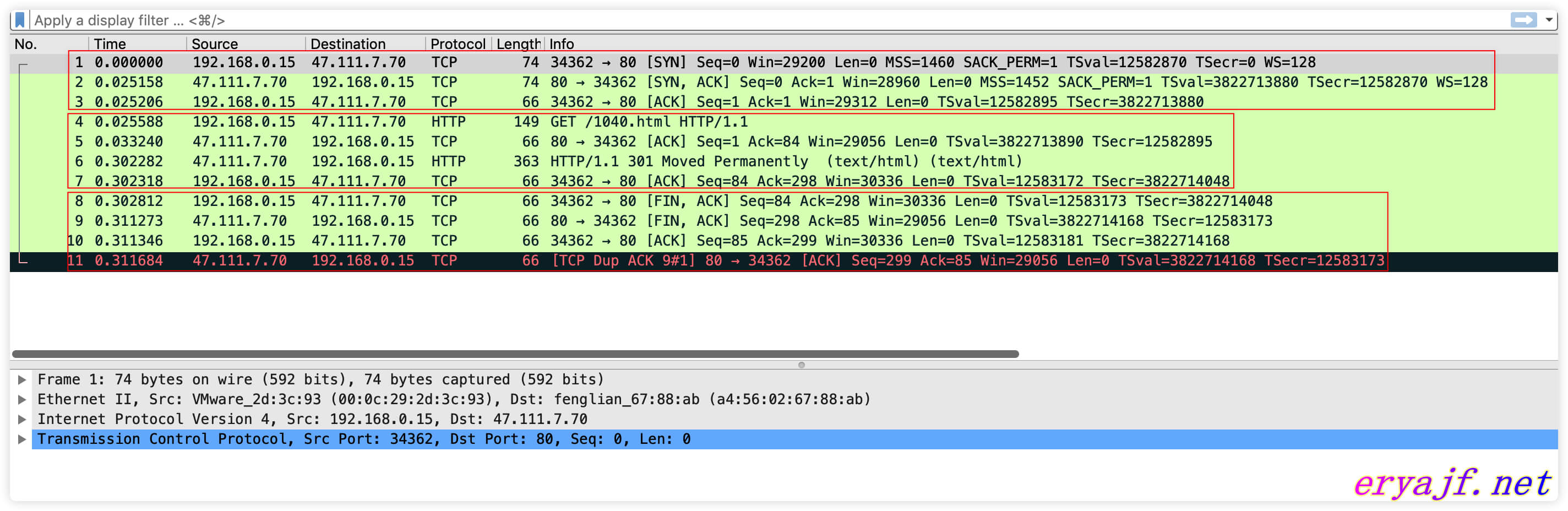
图中凭借着个人目前对 TCP 知识的理解,用红框划分了三个阶段,这三个阶段展示了完整的 TCP 请求的流程。
1–3:是建联时的 TCP 三次握手。
4–7:进入到 HTTP 请求与响应的数据交互过程。
8–11:是结束连接的四次挥手流程。
# 3,见图知意
接下来用大白话浅显的针对每条数据包进行一下简单分析,分析内容中将会依据如上三个阶段进行讲解,并且,因为在这整个过程中,TCP 的状态是在不断变化的,往常我们碰到主机 TIME_WAIT 或者 CLOSE_WAIT 过多的时候,经常头疼于这些名词的含义,因此争取在这次讲解当中也能够将 TCP 的状态对应上,以帮助我们理解那些名词。
讲解之前,先引用两张超级厉害的动图来进行一下概括,首先说明,图来自于 https://blog.csdn.net/qzcsu/article/details/72861891 ,人家已经画的足够好,自己就不必在这上头浪费精力了。
三次握手:

通过三次握手成功建立连接,两端进入数据传输过程。
四次挥手:
# 4,流程浅析
详细说明如下,为了便于对比抓包数据,再次把 wireshark 的图搬过来:
client发起 TCP 建联请求,通过本机的临时端口34362与远程server的80端口通信。 标志位为SYN,序列号为 seq=x(0),此处 SYN 表示客户端请求建立连接。然后,客户端进入SYN_SEND(同步已发送状态)状态,等待服务器的确认。server收到建联请求,通过 web 端口80与client的34362端口通信。 服务器收到客户端的SYN报文段,需要对这个 SYN 报文段进行确认,确认报文中应该 ACK=1,SYN=1,确认号是 ack=x+1(1),同时也要为自己初始化一个序列号 seq=y,此时,TCP 服务器进程进入了SYN_RCVD(同步收到)状态。TCP 客户端进程收到确认后,再次向服务器发出确认。 确认报文的 ACK=1,ack=y+1,自己的序列号 seq=x+1,此时,TCP 连接建立,客户端进入
ESTABLISHED(已建立连接)状态。此时可看下图帮助理解,(图源网络)。
握手完毕,两端都进入
ESTABLISHED状态,可以看到 client 向 server 端发起了一个HTTP协议(HTTP 建联是基于 TCP 协议的)的GET请求。从 info 中我们看到了
ACK的标志,说明这个包是 server 回应给 client 上一个包的请求。这个包同样是从 server 流向 client 的,我们在 info 中看到了,
HTTP 301 Moved Permanently,301 是一个重定向的状态码,Moved Permanently表明 server 将请求的资源反馈给 client 端。前后许多动作都是为了这一步,我们也可以看到这个包的长度为363,是整个请求流程中最大的,表明这次的真正的数据传输。从 info 中我们再次看到了
ACK的标志,说明这个包是 client 回应给 server 端表明自己收到了上一个包。整个你来我往的流程就是这样客气。当数据传输完毕,客户端不再发起请求,就会进入四次分手阶段。注意分手的话不一定都是客户端先说,因此下边将双方用主机 A 和主机 B 来表示。
主机 A 的客户端进程向主机 B 的服务端发出连接释放的报文,并且停止发送数据。 主机 A 设置 Seq 和 Ack,向主机 B 发送一个 FIN 报文段,FIN 是关闭连接的标志。此时,主机 A 进入到
FIN_WAIT_1状态,这表示主机 A 没有数据要发送给主机 B 了。到这个地方需要注意一个细节,因为一些请求的发生时机并非完全顺序执行的,因此可能会有包的记录时间先后顺序不规范的情况。这个地方 9 与 10 两个包就应该换一下位置才符合正常分手的程序,不然就成了两个人同时说分手,然后一拍两散了。
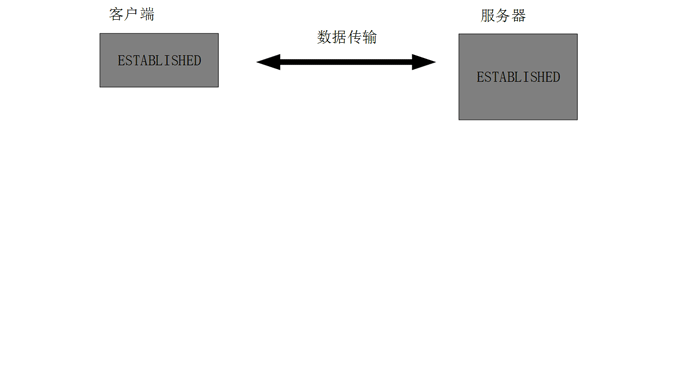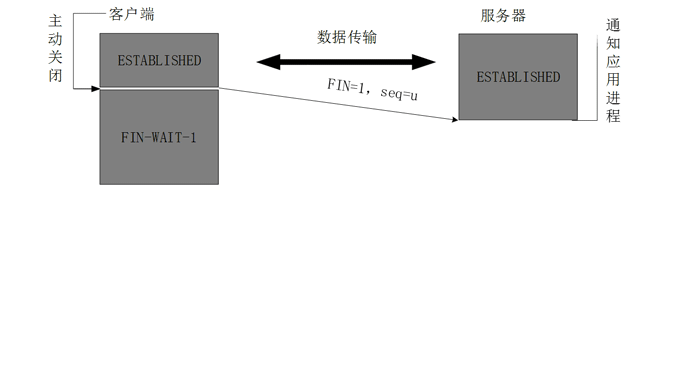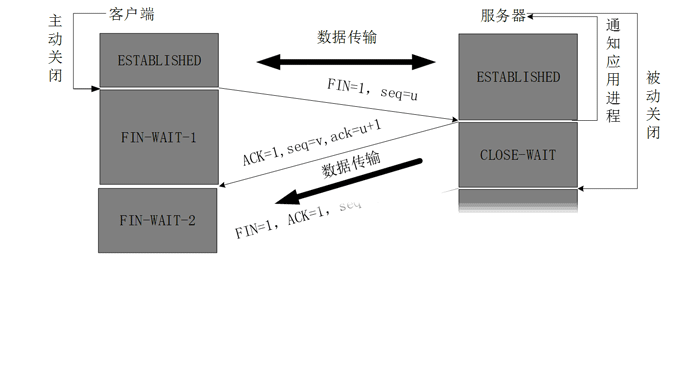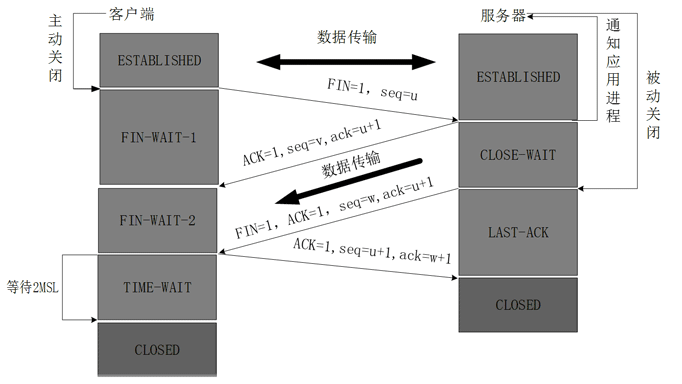
主机 B 收到连接释放报文,向主机 A 发送确认报文。 主机 B 收到了主机 A 发送的 FIN 报文段,向主机 A 回一个 ACK 报文段,Ack 为 Seq 都加 1,此时主机 B 进入到
CLOSE_WAIT状态,表示我同意你的关闭请求。CLOSE_WAIT是被动关闭端在等待应用进程关闭时的一个状态,比如 golang 中应用打开一个文件句柄与客户端交互,当服务端进入 close_wait 状态时,就是在等待文件对象调用 Close 方法。主机 B 向主机 A 发送连接释放报文。 主机 A 收到 B 的确认之后,进入
FIN_WAIT_2状态,是半关闭状态,即主机 A 失去发送能力,但是主机 B 却还能向 A 发送数据,并且 A 可以接收数据。此时主机 B 占主导位置了,如果需要继续关闭则需要主机 B 来操作了,于是,这一次就是,它向主机 A 发送 FIN 报文段,请求关闭连接,同时主机 B 进入LAST_ACK状态。主机 A 收到连接释放报文,向主机 B 发送确认报文。 主机 A 接收到请求后发送 ACK 确认,然后进入
TIME_WAIT状态,等待 2MSL 之后进入CLOSED状态,而主机 B 则在接受到确认后即进入CLOSED状态。此时可看下图帮助理解,(图源网络)。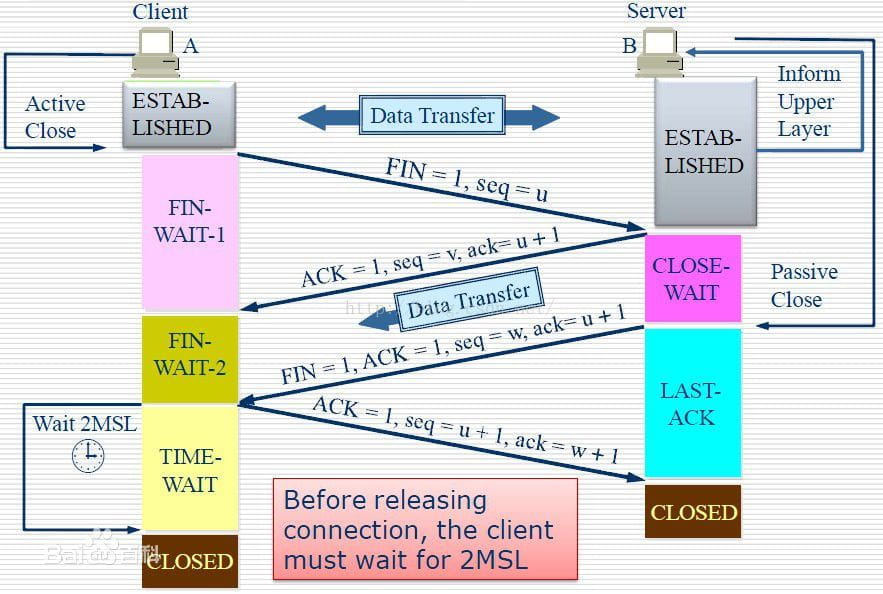
本文基于个人目前对 TCP 相关知识的理解而写,可能会有错漏的地方,如果有人发现,欢迎指出交流。
# 5,思维扩展
关于上边内容的与实际工作的关联,我能想到的大概有如下几点。
# 1,端口
以往对这块儿的理解不够深入,以为server就启动一个80的服务,然后 client 直接请求 server 的这个端口就好了,没想过本机也要启动一个端口。不过话说回来,在理解了之后,就想到端对端通信肯定是要基于两个端口来的,不可能对方起一个 80 端口,自己就硬生生去请求数据了。
基于此,再扩展一下来看,我们可以通过如下命令查看到 CentOS 中默认情况下的临时端口分配范围:
[root@eryajf ~]$cat /proc/sys/net/ipv4/ip_local_port_range
32768 60999
2
可以看到默认给出的范围是32768-60999,而面对一些实际生产环境,这个范围的端口可能是不够用的,如果不够用,那么超过这个范围的请求就会受到影响。于是,我们可以通过调整内核参数来进行修改:
# 添加如下配置
echo "net.ipv4.ip_local_port_range=10240 65000" >> /etc/sysctl.conf
# 重载生效
sysctl -p
2
3
4
正是基于如上知识的了解以及理解,这里才能够体会此处内核参数调优(特意把这个标红,是为了把这个高大上的词汇平凡化)的意义所在。
# 2,关注 TCP 状态
正如前边提到的,以往在我听到TIME_WAIT之类的词汇,常常是有一些迷糊的,并不能准确的定位这个状态是发生在整个请求流程的哪一步了,包括CLOST_WAIT,ESTABLISHED等名词。于是,这次在整理本文时,我特地将各个状态在整个流程中标明,以帮助理解。
基于如上理解,也可以扩展一下,实际生产业务当中,有哪些状态是需要我们重点关注的呢?这些状态的数值究竟达到多少才是我们应该去处理的呢?处理的时候应该怎样操作配置才能对症下药呢?
事实上在过去半年多的工作当中,我们曾多次以TCP在Prometheus中的对应状态的波动,来倒推开发回头审视自己的代码中的 bug 的,以及我们自己对一些配置项的合理度。
这里举几个实际生产中的例子来进行说明,某一天,在进行监控巡检的时候,忽的看到有机器的 TCP 状态如下图所示:
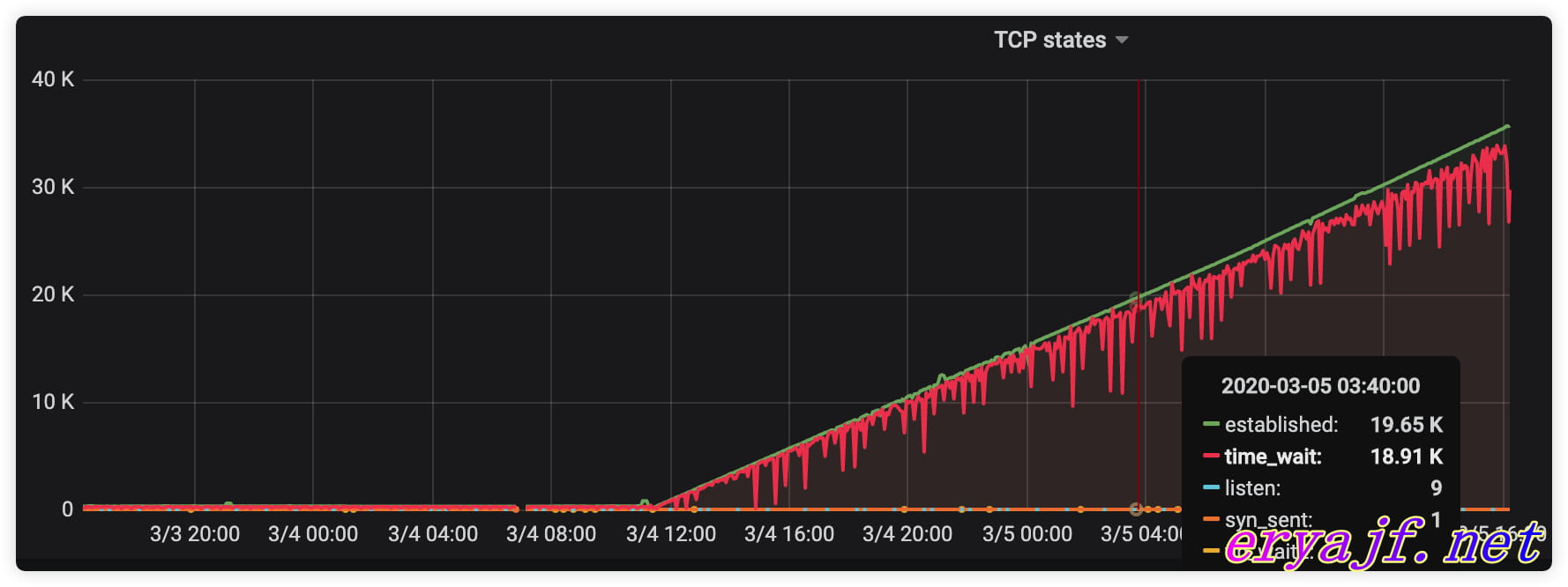
最开始看到的是当前的数值相当大,接着把时间跨度拉大,发现这一现象是从某一刻开始的,而并非一直这么大,后来开发一查代码,果然是在调用连接池的时候,忘记关闭了,如此一来,连接数自然就会越堆越多了。
还有一个例子是我针对一组服务器的 TIME_WAIT 状态过多地探析与研究,具体可以参考一下 CentOS 系统里 TCP 状态中 TIME_WAIT 超过 3 万的分析与建议 (opens new window)这篇文章。
再有一次就是某组 web 服务的机器ESTABLISHED状态相当的多,高峰时几乎接近四万,如果不进行处理,如果某一天突然一大波流量进来,可能直接就占满了,从而系统无法处理超出的连接。
其实连接数过多无非也就那么几种情况,要么是真实连接的确多,要么是没有及时将连接关闭导致,因为是 web 服务,极有可能配置在 NGINX 那里控制着,果不其然,我看到了配置中的 keepalive_timeout定义的是300(5 分钟),尽管这可能不算很长,但是针对请求量本身就很大的主机来说,显然也是不合理的。
于是我将这个情况与开发进行沟通,表明这个数值需要调小,是否会影响对应的实际业务 (针对一些特殊长链的场景,如果猛然调小超时时间,可能会带来其他不可知问题),得到的回应是不会影响,于是果断将超时时间改为60(1 分钟),没过多久,就在监控中看到了相应的效果。
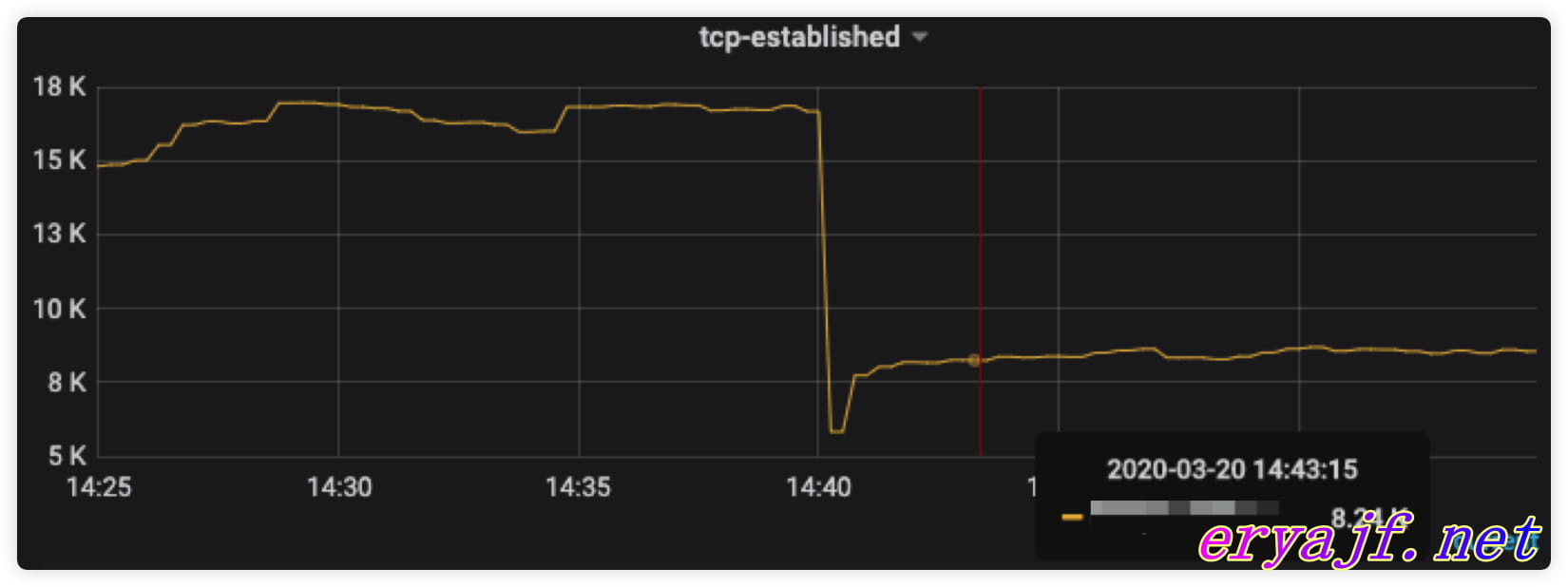
很多内容是在我们不经意之间串联着的,当我们一直奔忙在实际工作的任务时,可能有时候反而容易忽略一些简单的东西。
# 3,CLOSE_WAIT 过多
如果服务器出现大量的CLOSE_WAIT,一般有以下几点思路:
- 通常这种现象多出现在中间件服务所在服务器上,因为应用程序在连接中间件的时候,就会涉及到
Open,Close这样的操作,如果开发者在编码时忘记Close,或者代码有逻辑 bug,导致即便写了 close 也执行不到,那么就很容易出现CLOSE_WAIT。 - 可以查看一下服务器资源是不是很紧张,比如 CPU 很忙,或者磁盘 IO 很高,从而导致 Close 方法无法正确执行。
此问题,可详见此文的分析:为什么这么多 CLOSE_WAIT (opens new window)
好了,这篇文字东扯葫芦西扯瓢地已经说了不少,该去做点饭填补一下空虚的肚皮了。
# 5,参考


 |
|