 开源项目ZenOps:带你领略禅意运维
开源项目ZenOps:带你领略禅意运维
# 前言
运维领域的工具,有这样几个阶段,从最初的命令行工具,到 Web 界面交互,再到今天结合AI用自然语言交互,每一种场景都有其独特的价值。
截至目前,我还没有遇到比较理想的,简单接入即用的工具,于是,自己动手,丰衣足食,我写了一个小工具,ZenOps,希望借助大模型的能力,打造一个简单易用的框架,让运维场景中的各种数据,都能轻松查询。
# 项目介绍

- name: ZenOps
desc: 点我跳转到项目地址
avatar: https://avatars2.githubusercontent.com/u/416130?s=460&u=8753e86600e300a9811cdc539aa158deec2e2724&v=4 # 可选
link: https://github.com/opsre/zenops
bgColor: "#0074ff" # 可选,默认var(--bodyBg)。颜色值有#号时请添加单引号
textColor: "#fff" # 可选,默认var(--textColor)
2
3
4
5
6
ZenOps 是一个面向运维领域的数据智能化查询工具,通过统一的接口抽象,支持多云平台(阿里云、腾讯云等云资源)、CI/CD 工具(Jenkins等各种运维领域常见工具)的资源查询,并通过 CLI、HTTP API 和 MCP 协议提供多种访问方式,同时集成钉钉,飞书(待添加)等智能机器人实现对话式查询。

# 前置准备
本次演示需要准备如下内容:
- 阿里云或者腾讯云的秘钥(目前所有的交互都是查询操作,可以给一个全局(或按需)只读的权限)。
- 可用的大模型秘钥(个人实测验证下来,推荐
DeepSeek-V3或者glm-4.6(或glm-4.5-flash) 这些模型) - Cherry Studio,用于调试 MCP 的能力。
- 钉钉开发者后台创建应用,机器人,消息卡片。
上边前三项都比较简单,根据自己情况准备即可,接下来先介绍下钉钉相关的内容。
# 创建钉钉应用
首先来到钉钉开发者后台: https://open-dev.dingtalk.com/ (opens new window)
点击应用开发,创建一个应用。
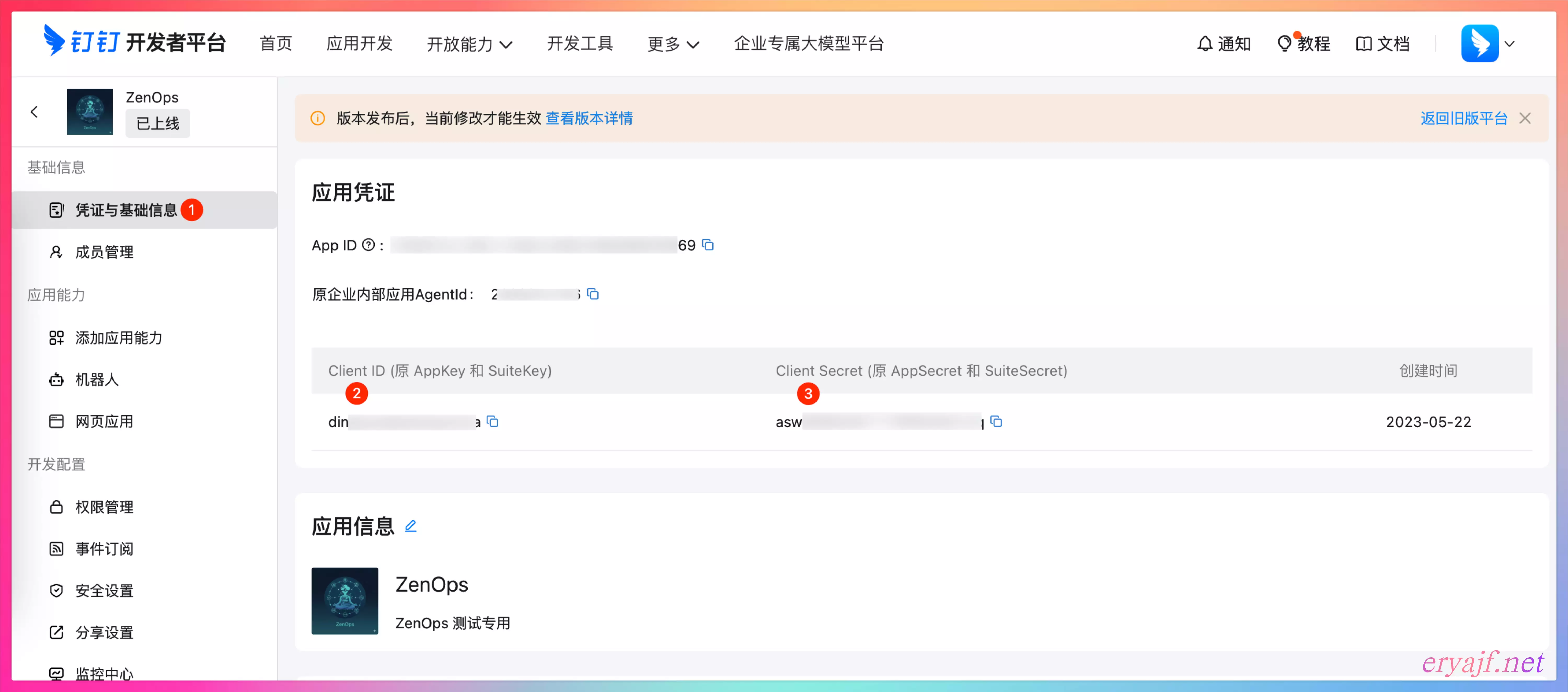
应用创建完成后,即可获得应用的 key 和 secret,见下图:
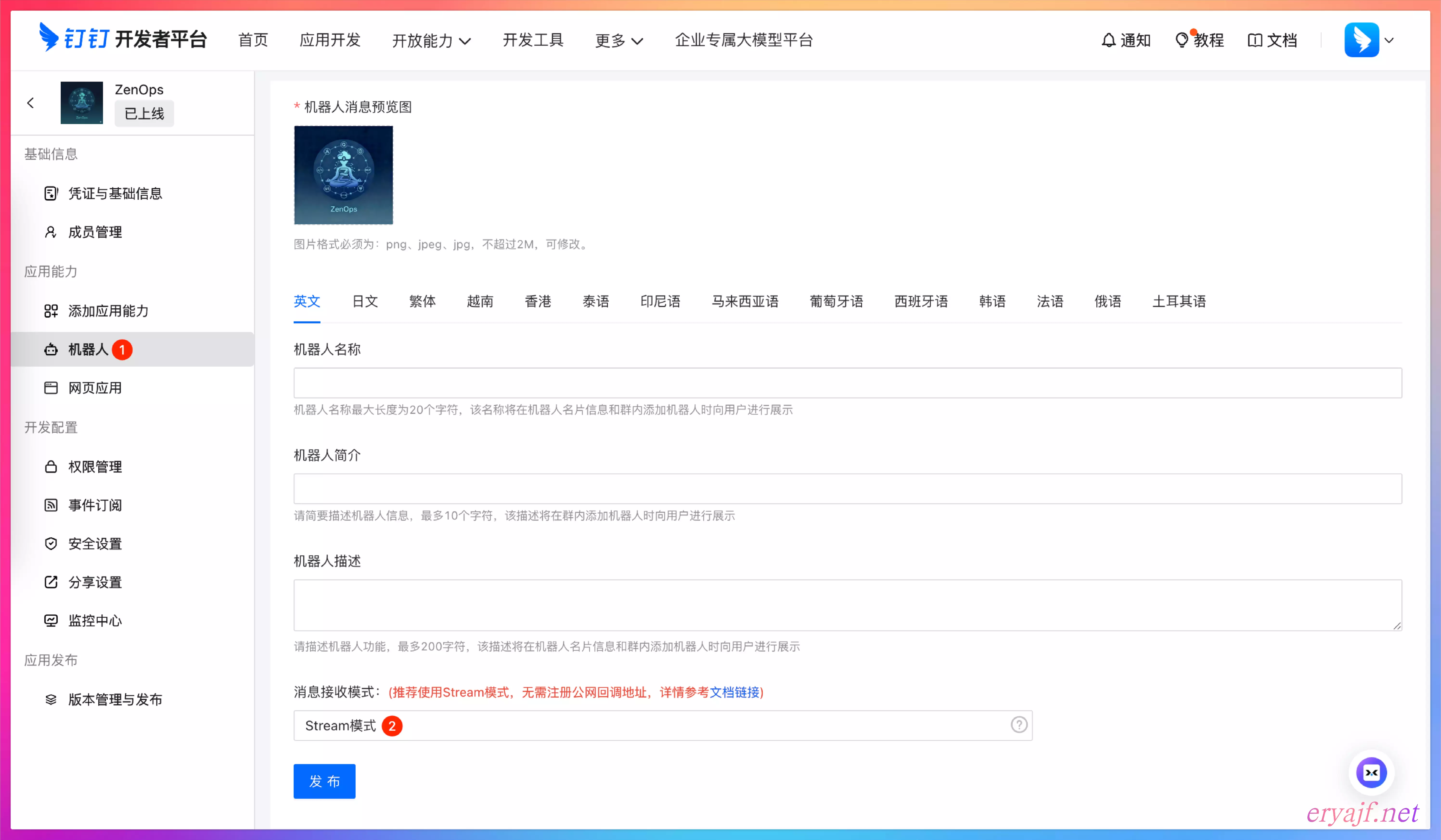
然后打开机器人,将其设置为 Stream 模式,随后将机器人发布。如下图:
创建完毕之后,就可以在对应企业的钉钉组织内搜索到这个机器人,这个时候既可以和该机器人单独对话,也可以将机器人加入到群聊,艾特机器人对话。
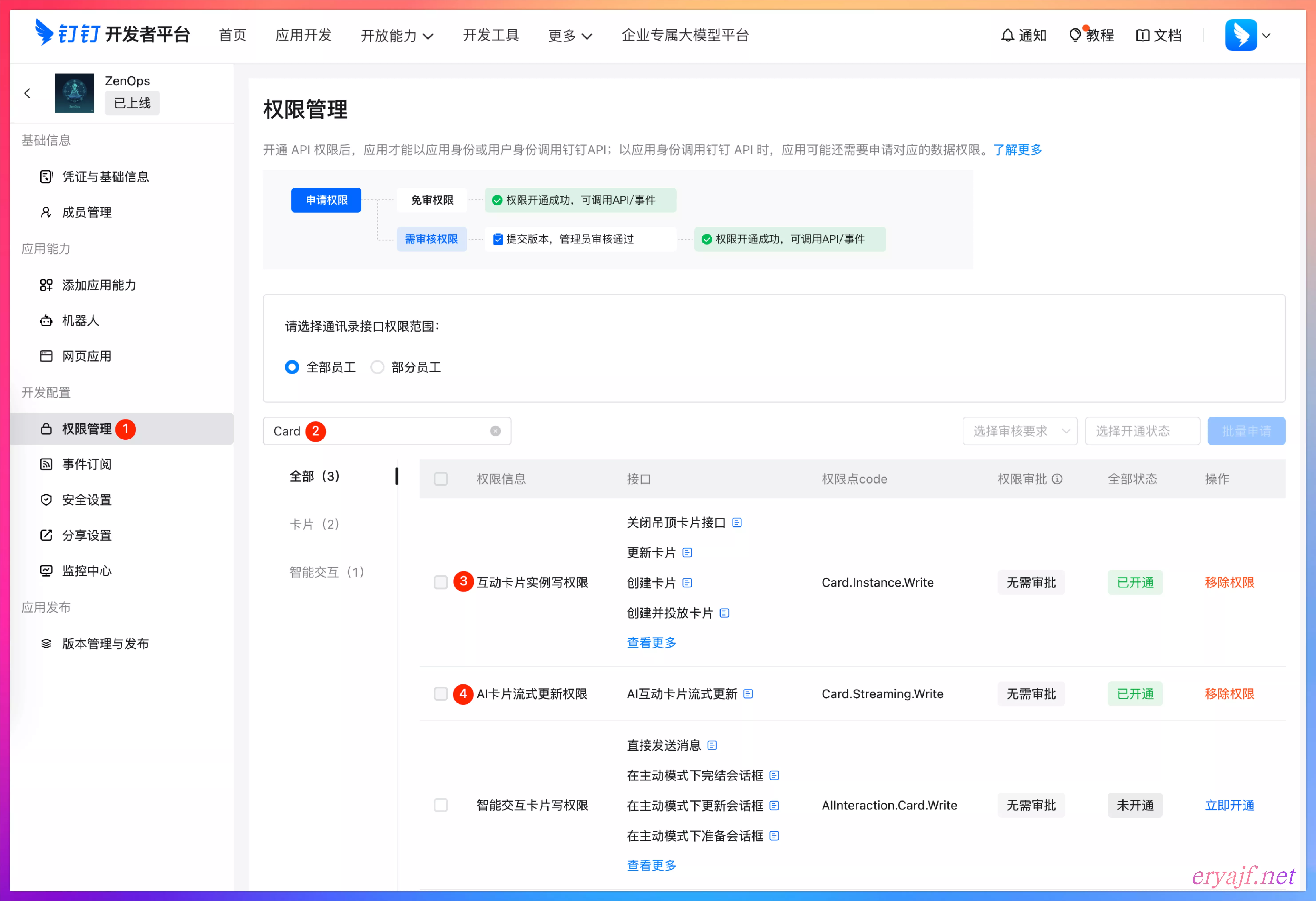
当前机器人交互时,需要添加卡片相关的权限,如下图,给对应两个权限即可:
最后点击最下边的版本管理与发布,把应用发布一个版本,就能在钉钉企业中搜索到对应机器人了。
然后点击最上边的开放能力,选择卡片平台,新建一个卡片模板:
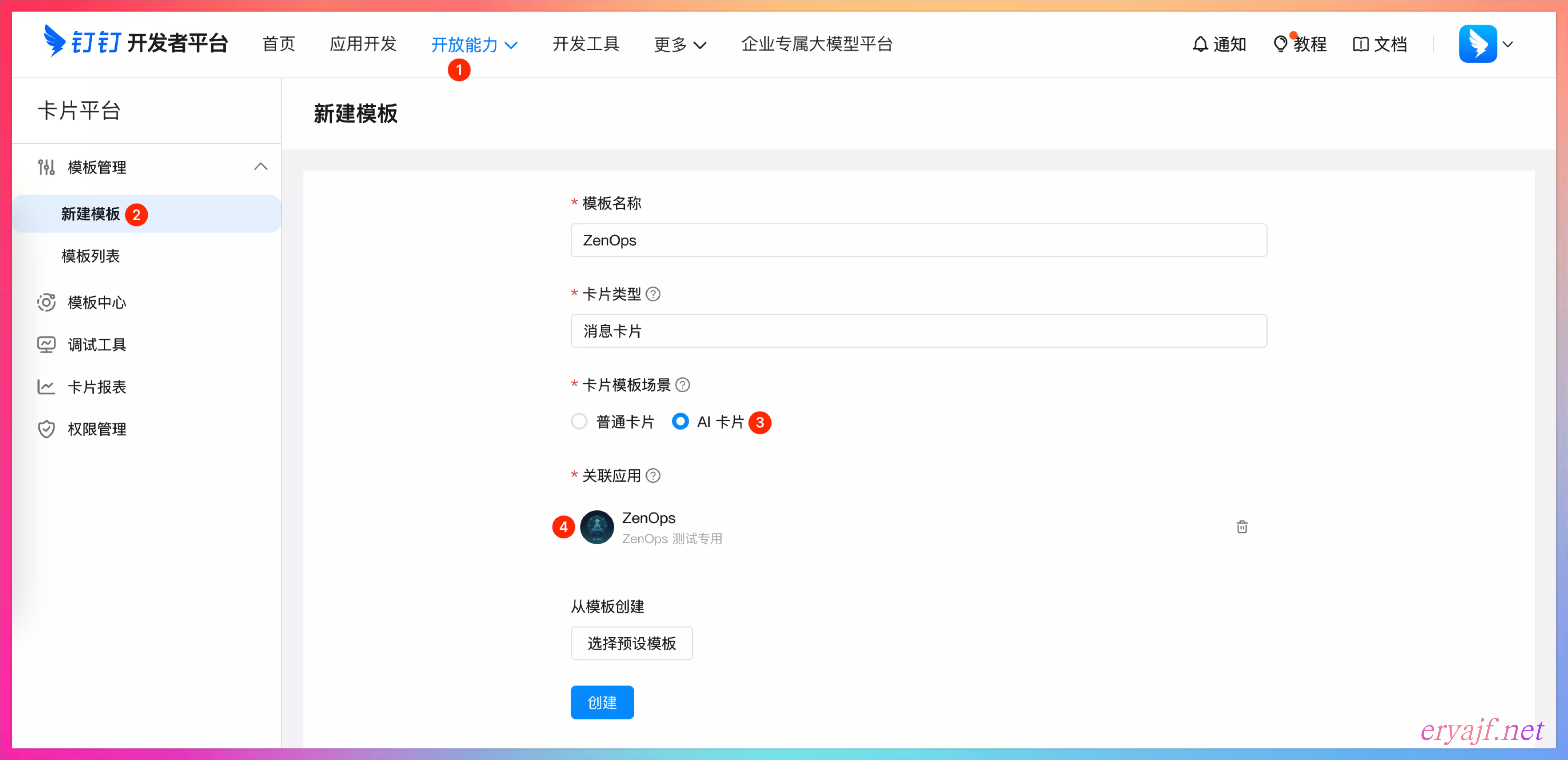
然后只保留一个标题,其余的内容删除,注意开启流式组件,然后保存卡片。
如果不想自己折腾,也可以直接导入我的卡片 json。地址:点我下载 (opens new window)
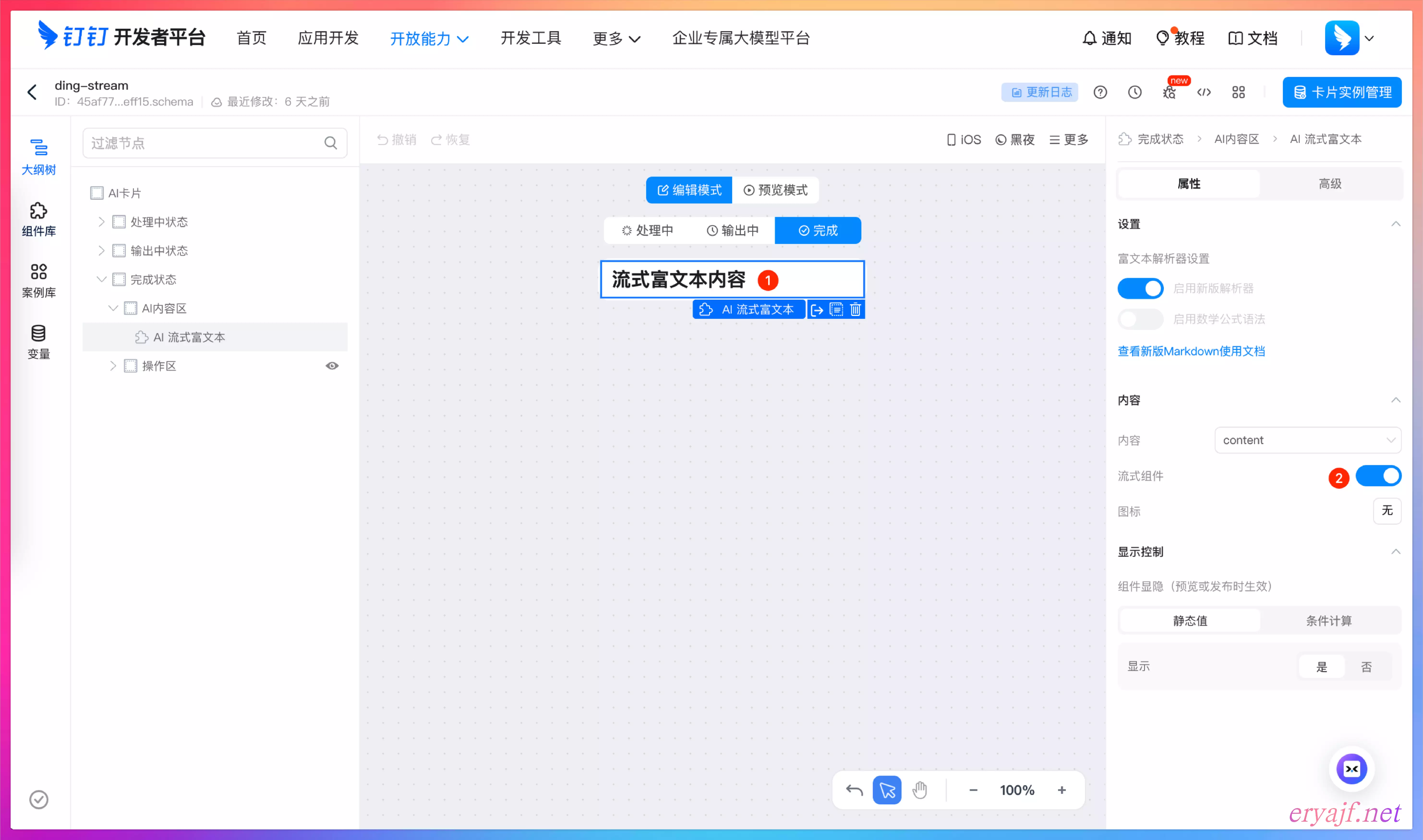
然后保存上图右上角的 ID,即卡片模板的 ID。
# 启动应用
项目提供了二进制以及 docker 镜像,可根据自己的喜好选择对应的部署方式。
首先在本地完善配置文件,如下内容是为了演示精简的配置,完整配置见:点我查看 (opens new window)
$ cat config.yaml
# 云服务提供商配置
providers:
# 腾讯云账号配置(支持多账号)
tencent:
- name: "default"
enabled: true
ak: "xxxxxxx"
sk: "xxxxxxxxxxx"
regions:
- "ap-nanjing"
dingtalk:
enabled: true
app_key: "xxxx"
app_secret: "xxxxxxxxx"
card_template_id: "xxxxxxx" # AI 流式卡片模板 ID
enable_llm_conversation: true # 是否启用 LLM 智能对话模式
llm:
enabled: true
model: "glm-4.6"
base_url: "https://open.bigmodel.cn/api/paas/v4"
api_key: "xxxxxxxxxxxxxxxxx"
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
我这里选择使用 docker 部署,把配置文件挂载到容器启动服务:
$ docker run -itd --name zenops -p 8080:8080 -p 8081:8081 -v ./config.yaml:/app/config.yaml docker.cnb.cool/opsre/zenops
启动之后,会监听两个端口,8080 是 http 请求使用,8081 是 mcp 监听端口。
# 调试 MCP
这个就比较简单了,这里用 Cherry studio 来调试,进入设置,找到 MCP,添加如下配置:
{
"mcpServers": {
"test": {
"isActive": true,
"name": "zenops",
"type": "sse",
"description": "🧘 运维数据智能化查询工具",
"baseUrl": "http://localhost:8081/sse",
"command": "",
"args": [],
"env": {},
"provider": "eryajf",
"providerUrl": "https://github.com/opsre/zenops",
"logoUrl": "https://raw.githubusercontent.com/opsre/ZenOps/main/src/zenops.png",
"tags": [],
"longRunning": true,
"timeout": 300,
"installSource": "unknown"
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
如果服务不是运行在本地,则可以将 baseUrl 地址改为对应的服务器地址。
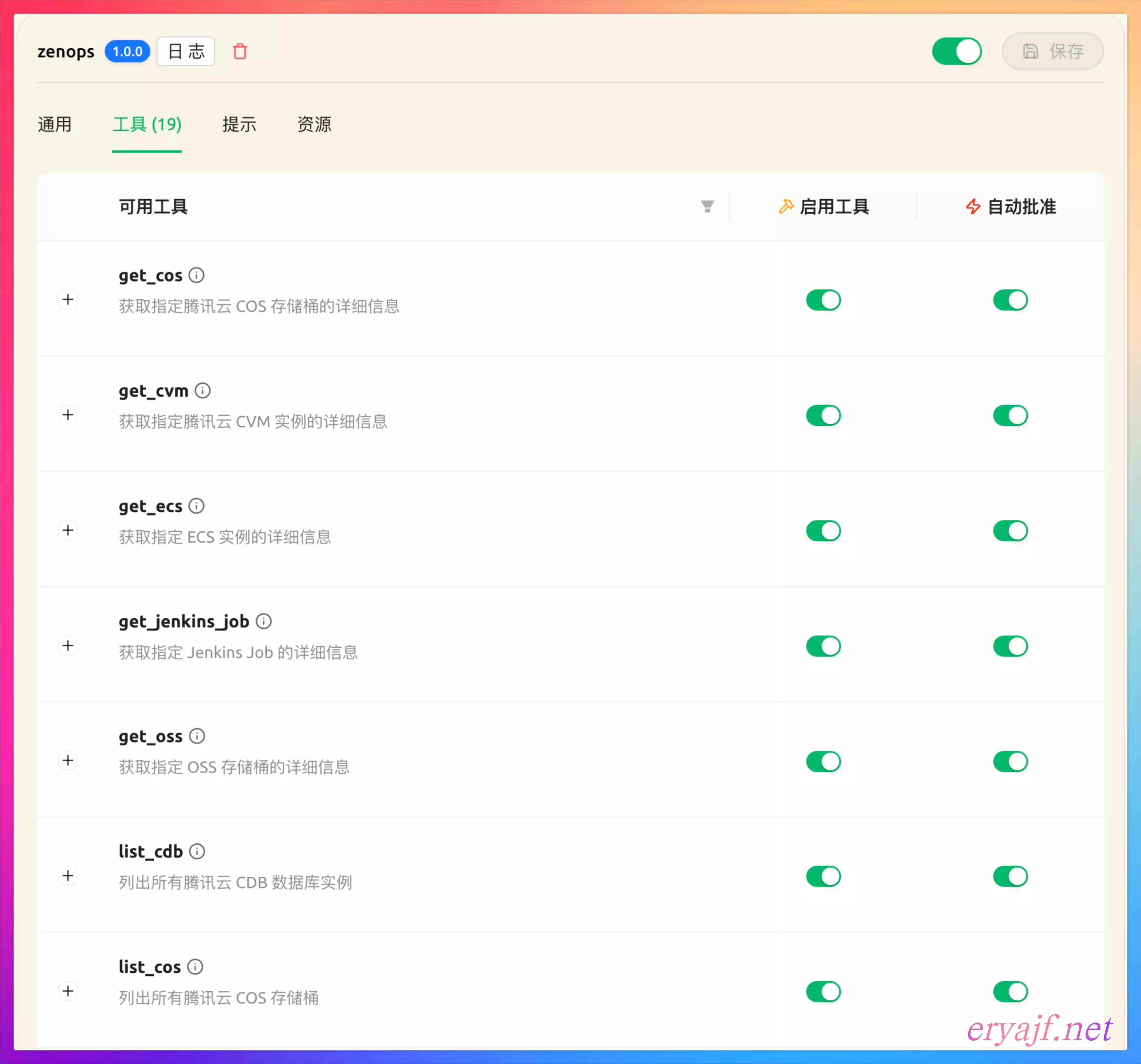
保存并启用,如果看到工具列表有数据,则说明配置成功:
然后来到对话框,随便来问一下:
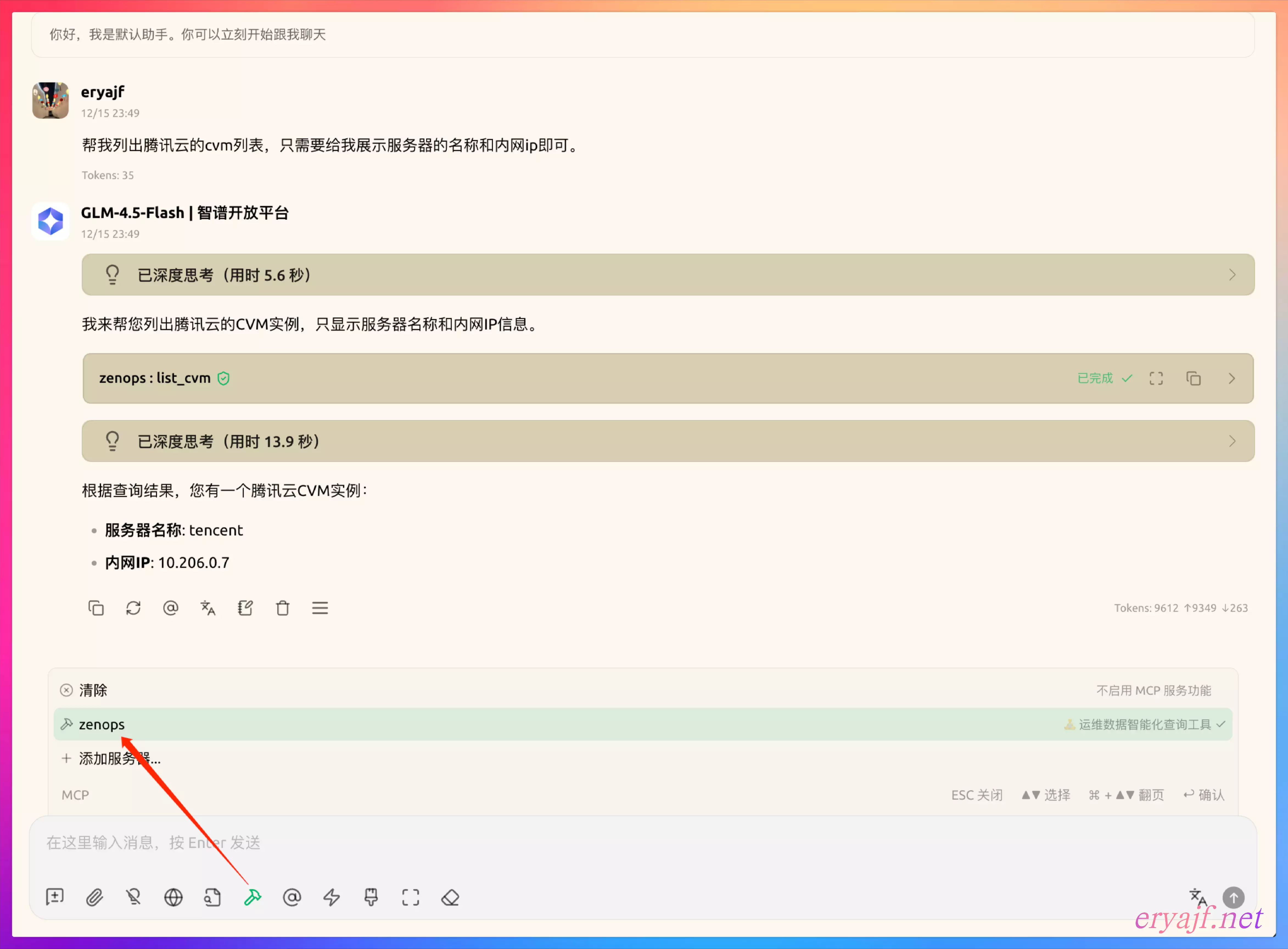
如此便完成了当前工具的简易交互流程。
# 钉钉对话
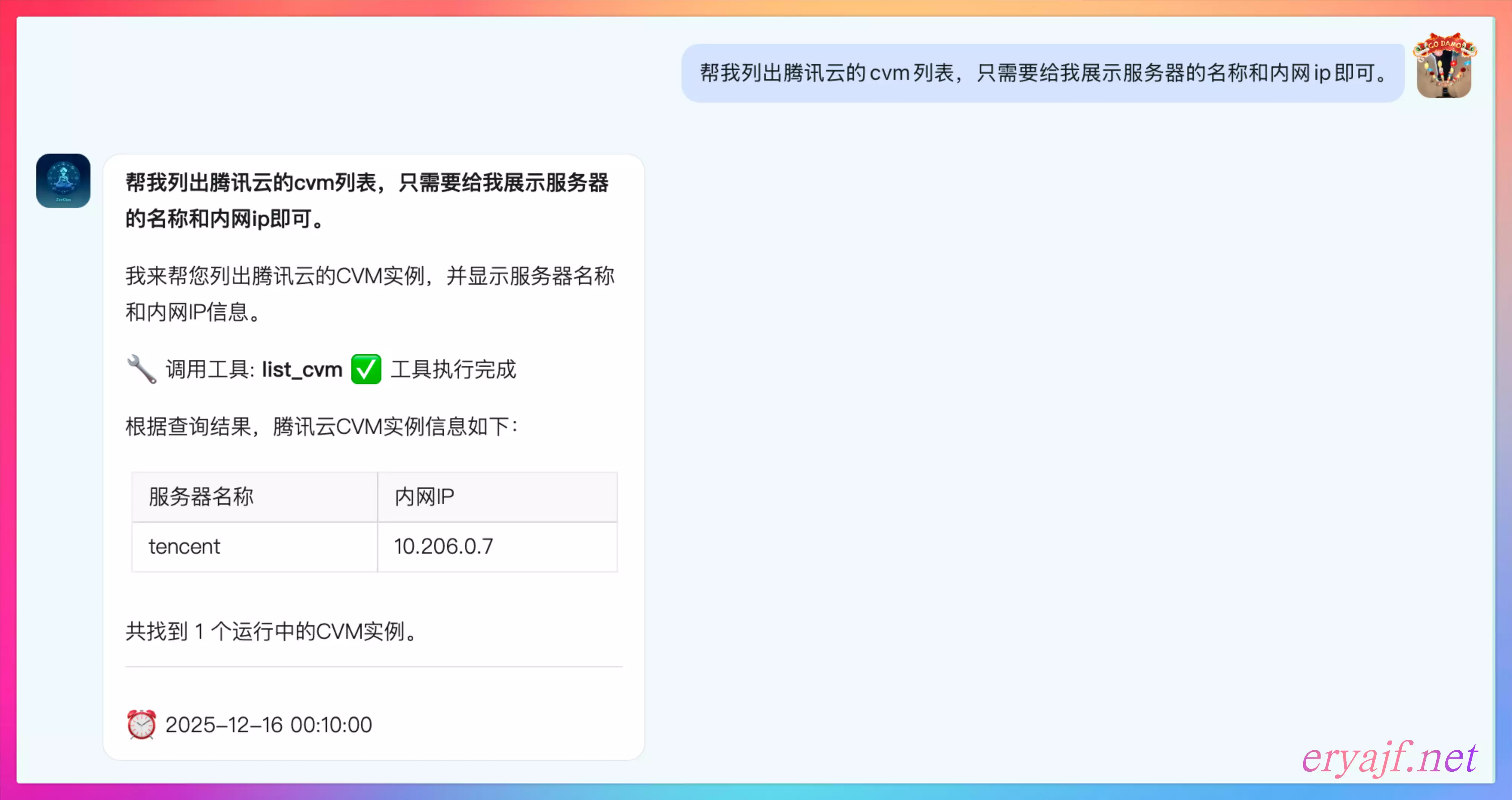
同理,当我们应用启动之后,默认用 Stream 模式监听,即可在钉钉私聊或者群聊中与机器人对话:
# 最后
我想,这应该是一个值得大家去尝试的小工具,我也将持续打磨工具底层框架,让模型层面交互更加准确更加丝滑,剩下的就是完善更多的运维领域的数据查询,争取打造一个用自然语言交互的运维数据智能化查询工具。
欢迎大家部署体验(觉得不错别忘了给项目点个 star),欢迎交流思路,提交问题与建议,也欢迎有想法的开发者贡献代码,让我们一起进入禅意运维之境。
# 补充:飞书智能机器人的配置方式
因为上文已经介绍过钉钉机器人的配置方式,这里就不多废话,直接进入主题,介绍飞书的配置方式。
访问飞书开发平台 (opens new window) 选择对应组织,新建一个应用。
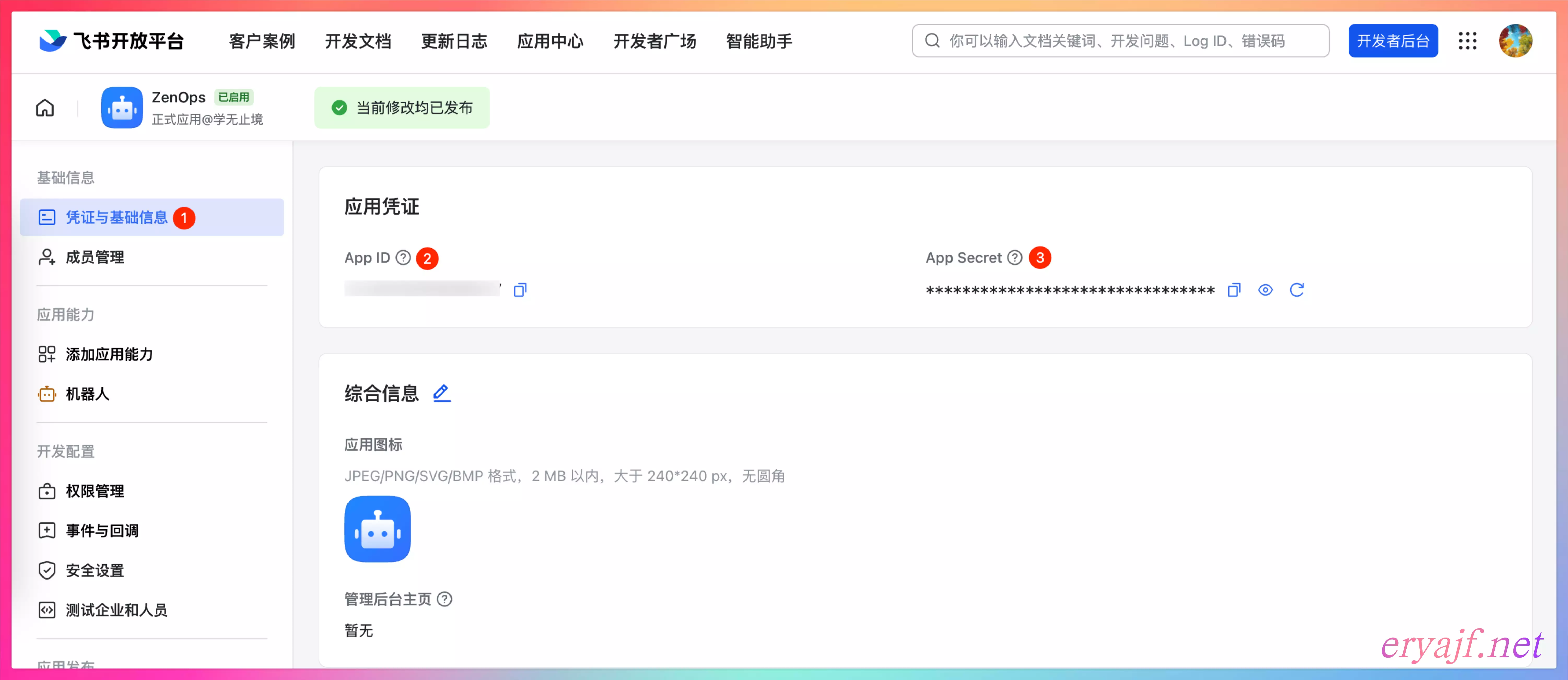
拿到 APP ID 和 Secret,复制好,配置到应用的 config.yaml 配置中。
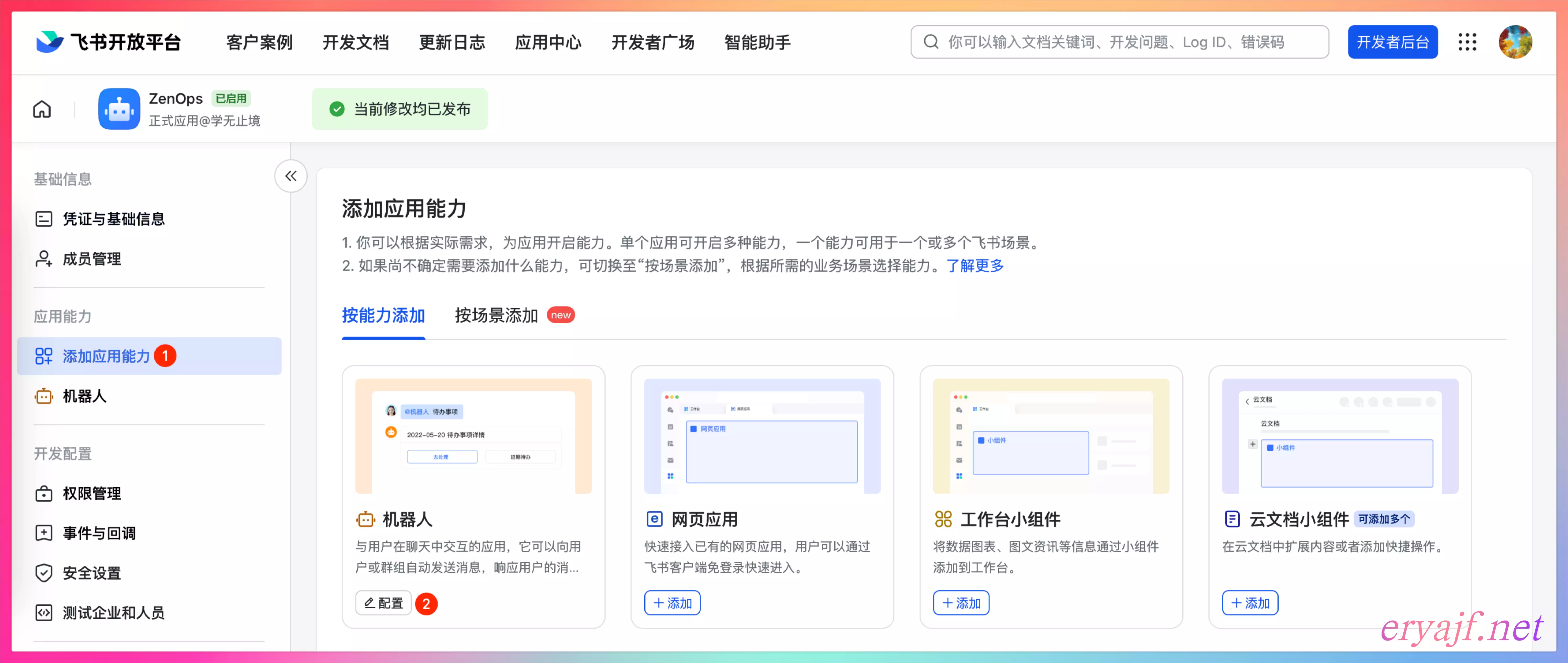
点击 添加应用能力,选择添加机器人,不需要其他配置。
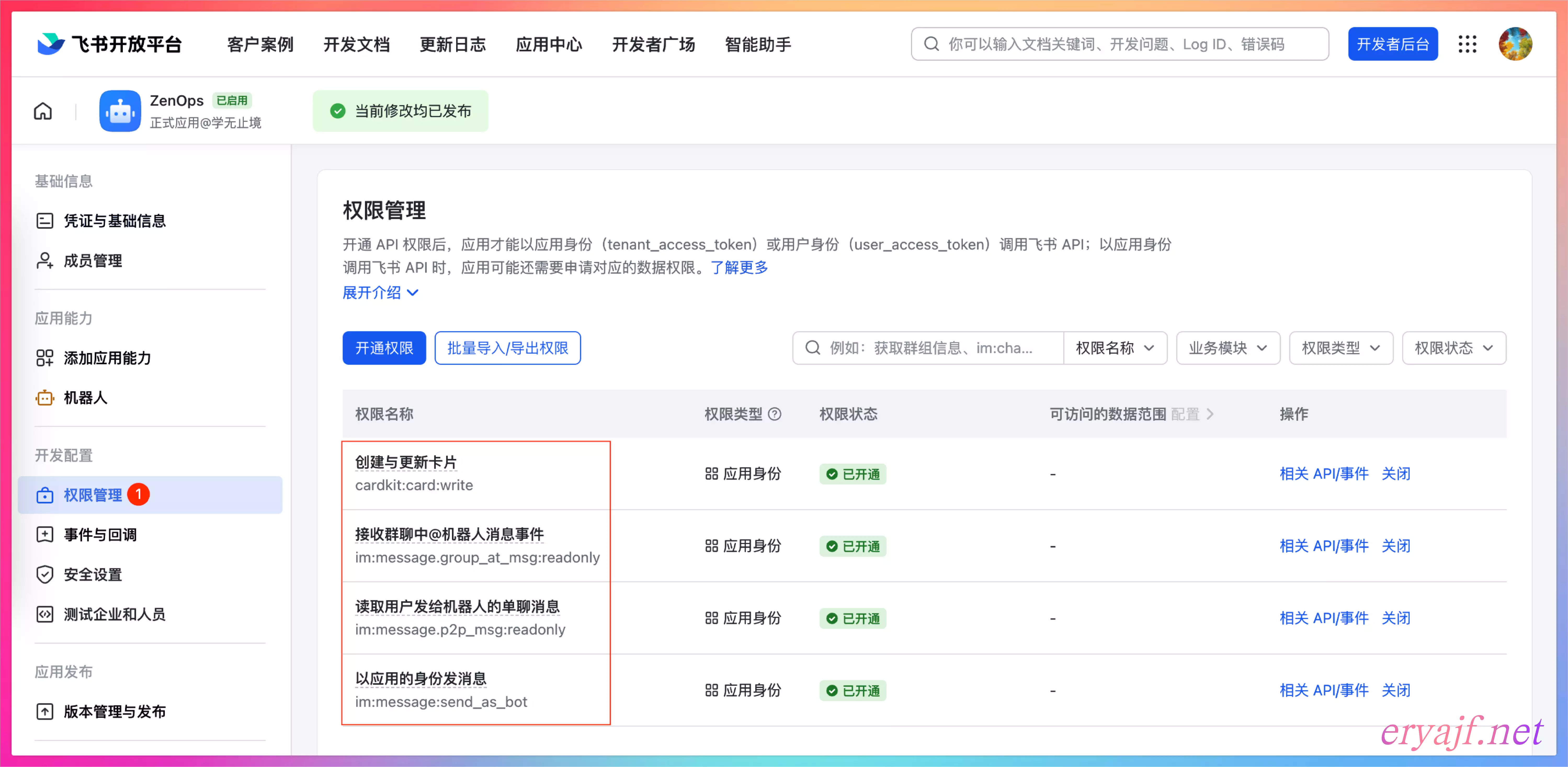
点击权限管理,开通相对应的权限,上图框起来的几项即是需要开通的权限。
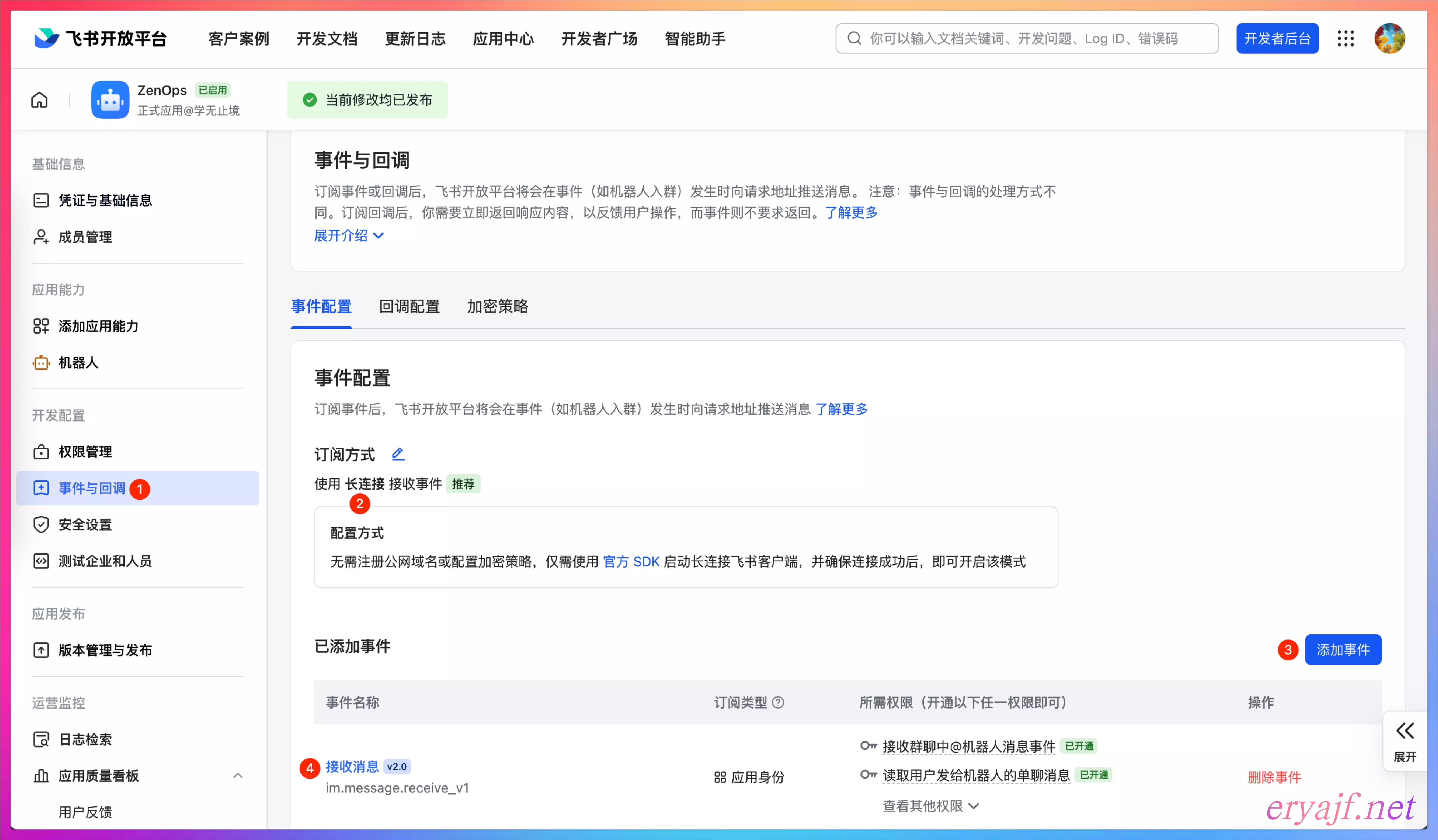
点击左侧 事件与回调,订阅方式 中选择 长连接,然后右侧 添加事件 中选择 接收消息。
最后就是点击 版本管理与发布,发布版本,即可使如上配置生效,接着就是启动服务,然后在飞书中搜索机器人名称,即可与之对话。
# 补充:企微智能机器人的配置方式
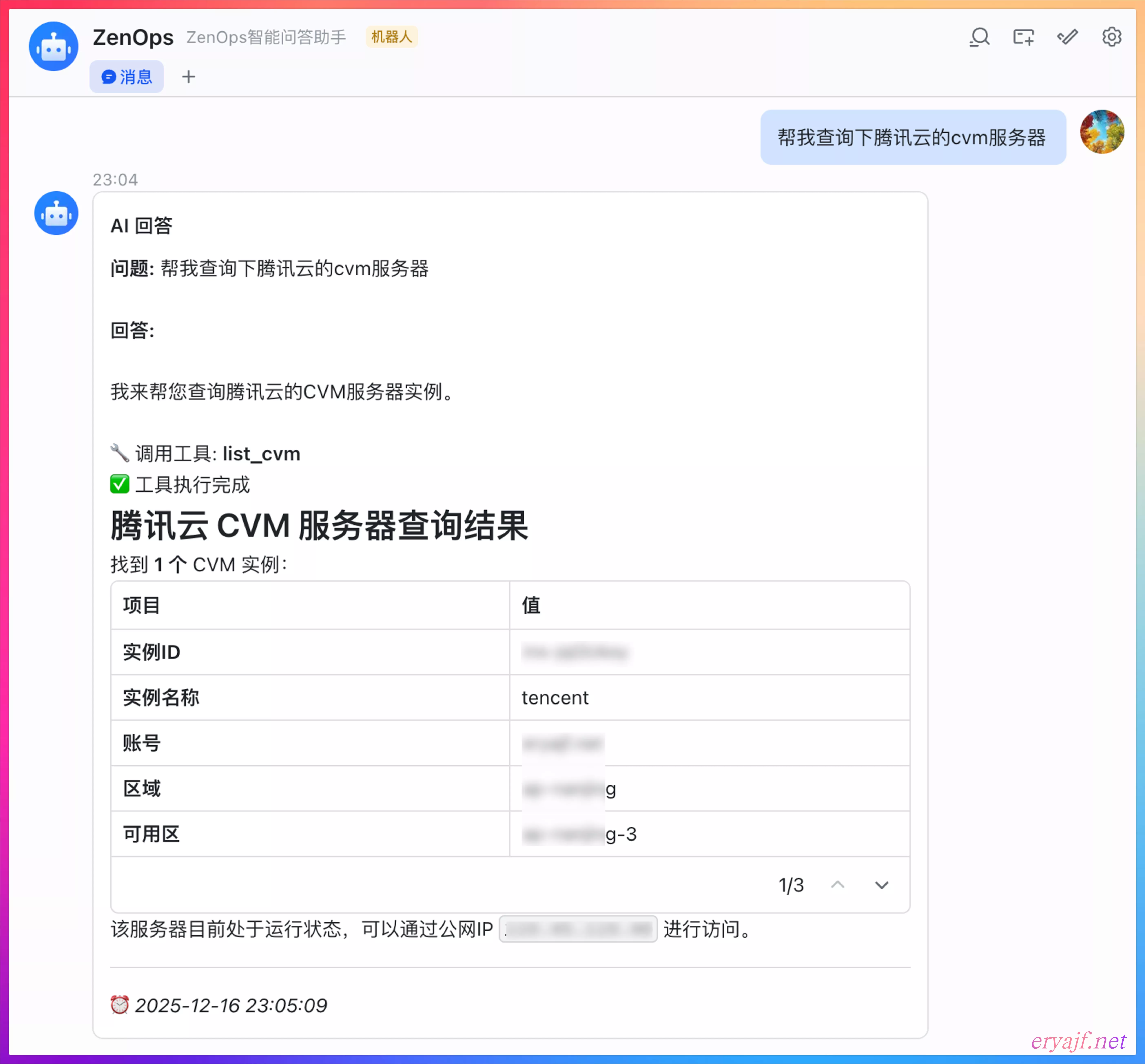
要注意:钉钉和飞书均支持本地启动即可与机器人互动的模式,企微则需要将服务暴漏到公网可回调才能进行交互。
登陆企微后台 (opens new window),点击可以直接进入创建应用界面。进入创建应用界面之后,滑到最底下,点击 API 模式创建。
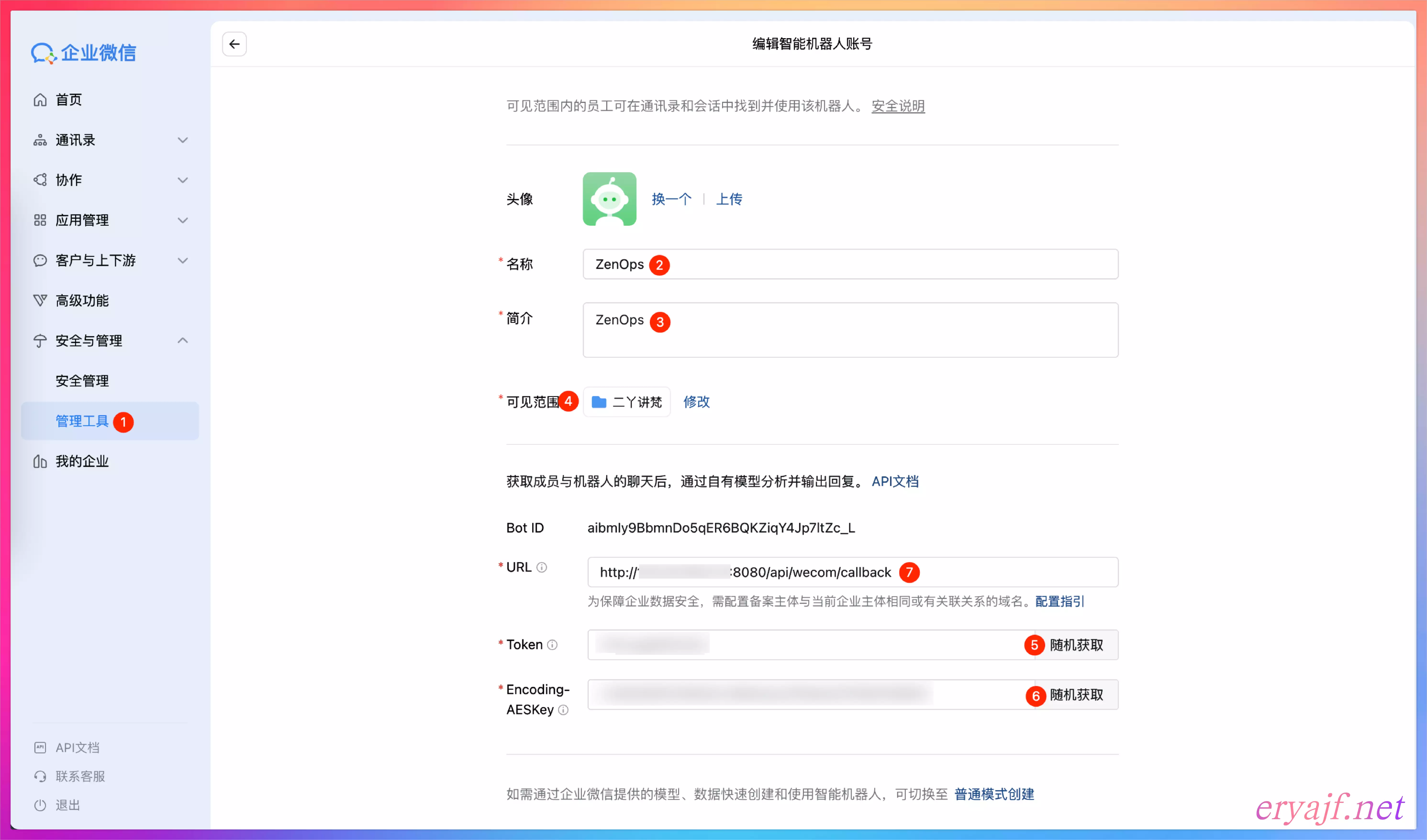
按照上图的标号顺序,注意:前四步完成之后,要先手动点击 5 号和 6 号的随机获取,然后可以拿到对应的 Token 和 Encoding-AESKey 信息,此时将这两项内容,配置到项目的 config.yaml 中,然后启动服务,需要将服务暴漏出来,能够被企微回调到。
然后把可访问的地址 http://your_ip:8080/api/wecom/callback 填写到 7 号输入框,再点击保存,即算配置完毕。
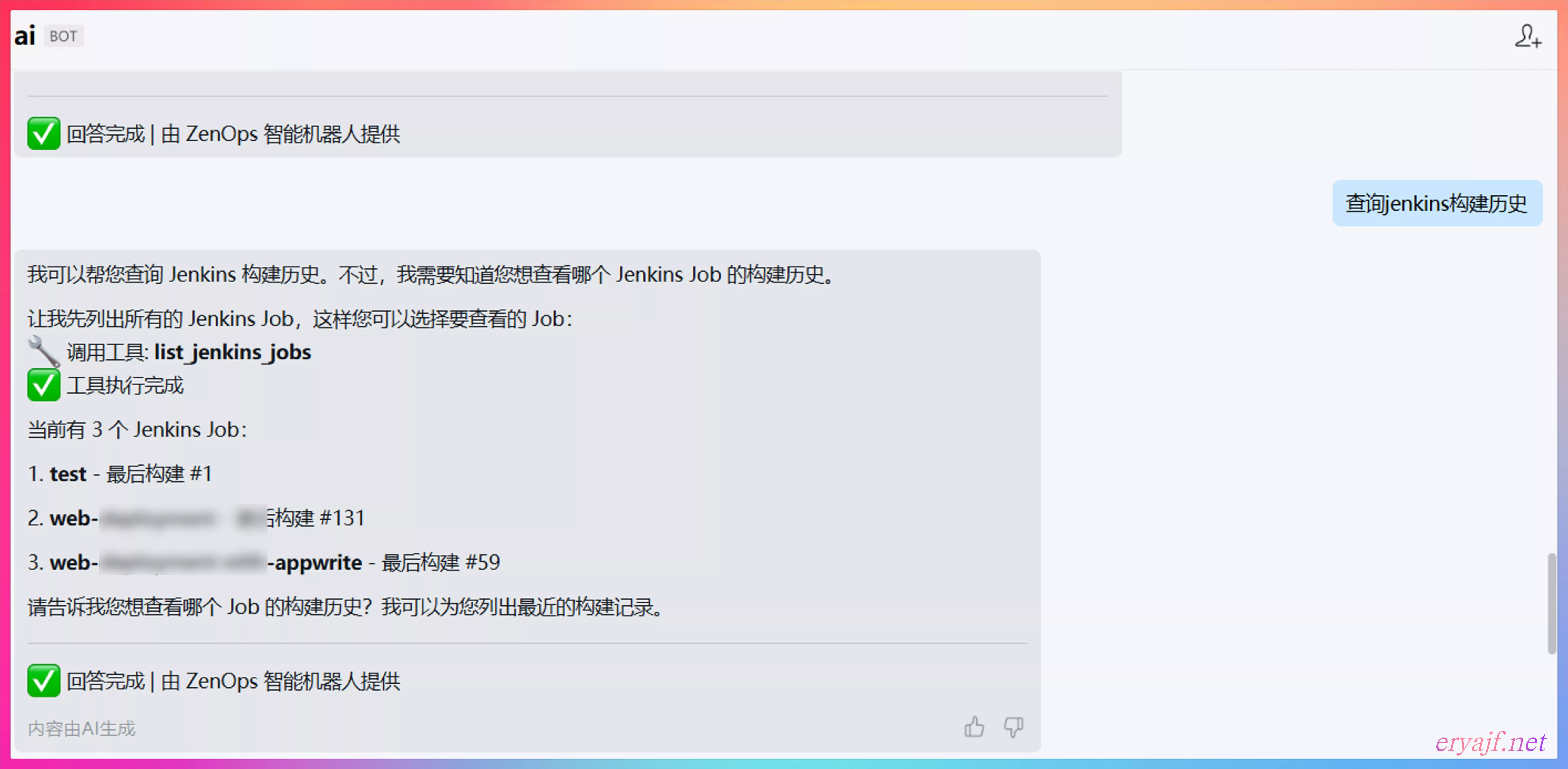
接着到企业微信,搜索机器人名称,即可与之对话。


 |
|