 rag-带你认识了解并劝退
rag-带你认识了解并劝退
# 前言
我对 rag 算不上特别了解,本文只是一个基于当前阶段,个人的一些理解与认识,希望记录下来,纯粹是为了给自己的一些付出做一个阶段性交代。
因此这不是一篇资深人士或者专业人士的专业分析,而是一篇面向像我一样的门外人士的简单入门,认识了解 rag 的文章。
如果你已经十分熟悉,那么完全可以跳过不看,我也在纠结个人粗浅的认识要不要记录下来,但就像最初记录博客文章的初心那样,不要因为内容粗浅而不记录,这正是自己学习成长的一个见证。
# 什么是 rag
到处都在讲 rag,那么首先,什么 rag 呢?
rag,即 Retrieval Augmented Generation ,意为检索增强生成。这是一种应用于知识内容检索领域的概念,有别于传统的基于关系型数据库构建的问答体系,rag 主要是基于向量数据库结合当下火热的大语言模型(LLM)来实现的智能问答的一种技术体系。
是的,围绕 rag 的核心是三个部分,原始文本内容,向量数据库,和大语言模型,其他的技术实现,以及细节调优基本都是在这几者之间的延伸。
以客服这个实际场景来举例:
- 每个公司最早一批的客服,肯定也都是摸着石头过河,很多问题都是新产生的,并没有可参见的案例或话术。
- 随着时间推移,客服工作人员的经验积累,话术慢慢沉淀,形成本公司业务专有的客服知识库,这个知识库可能会借助一些已有的 wiki 工具存放,那么后来的客服人员,遇到自己不会的问题,就可以通过查询 wiki 就能获取到他想要的答案。(局限:这里的问题是,这种查询一定是依赖于关键字匹配的,尽管能全文匹配,但一些时候,可能并不理想)
- 再往后,一些公司可能会基于成熟的客服话术,开发自己的智能客服机器人,而这种方案,虽然比上边的人工查询要进了一步,但局限是雷同的(还是依赖于技术型交互语言,而非自然语言交互)。
- 当大语言模型出现之后,人们最先想到的就是如何能将自己的知识库投喂给大语言模型,从而能够通过自然语言获取到想要的答案,自此念头开始,文本向量化,langchain 框架,本地大语言模型等技术应场景而生,渐渐进化为可完全基于本地构建的智能问答体系,从而解放客服的生产力。
# rag 的架构
听了那么多 rag,也讲了那么多 rag,那么 rag 究竟是什么呢,我想,通过一些架构图来理解是最简单直观的,但架构图也需要一定的挑选,这里我选取两张比较容易看懂容易理解的图,来辅助理解。
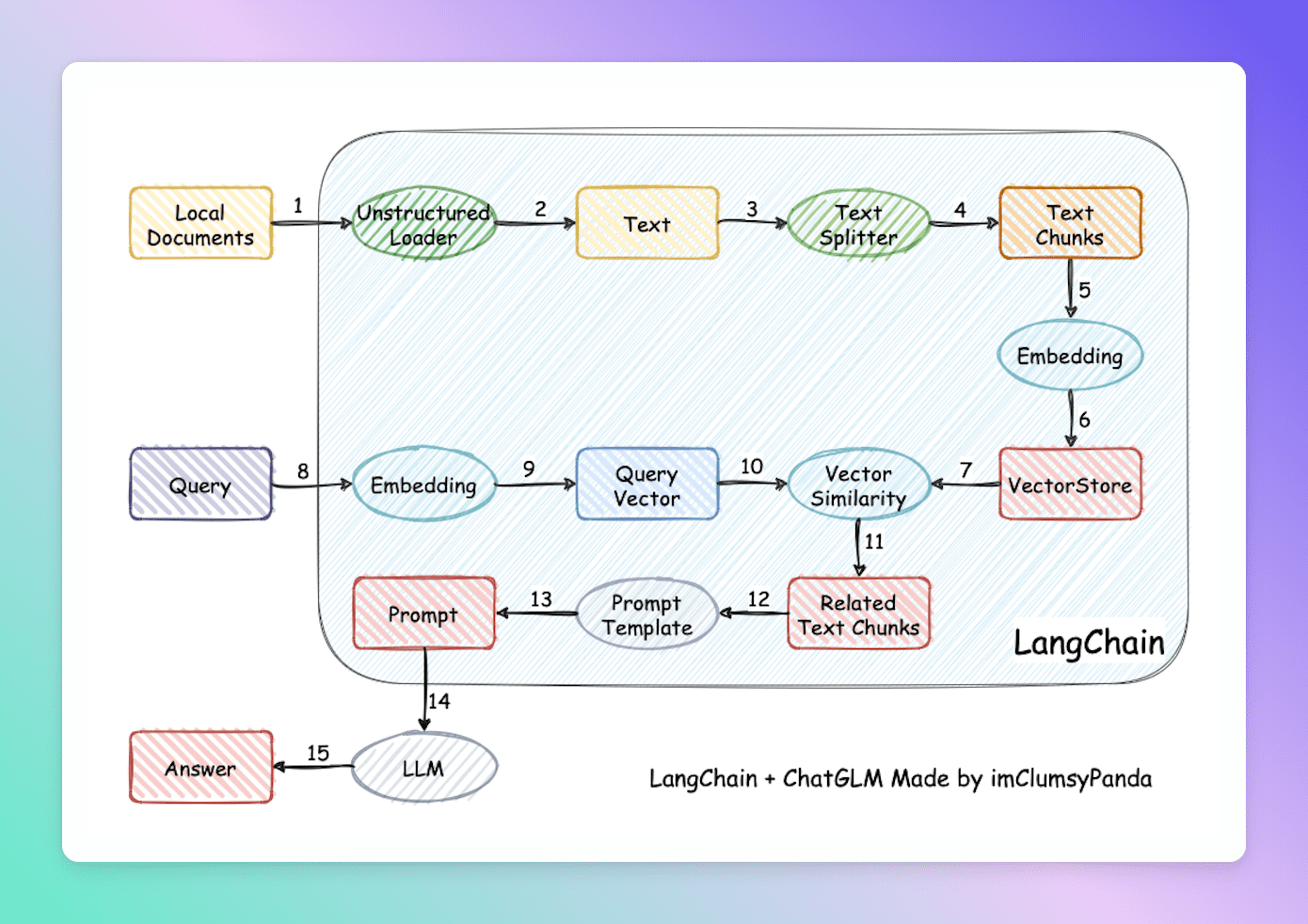
图一,来自项目:Langchain-Chatchat (opens new window)
图二:来自 PAI-RAG (opens new window)
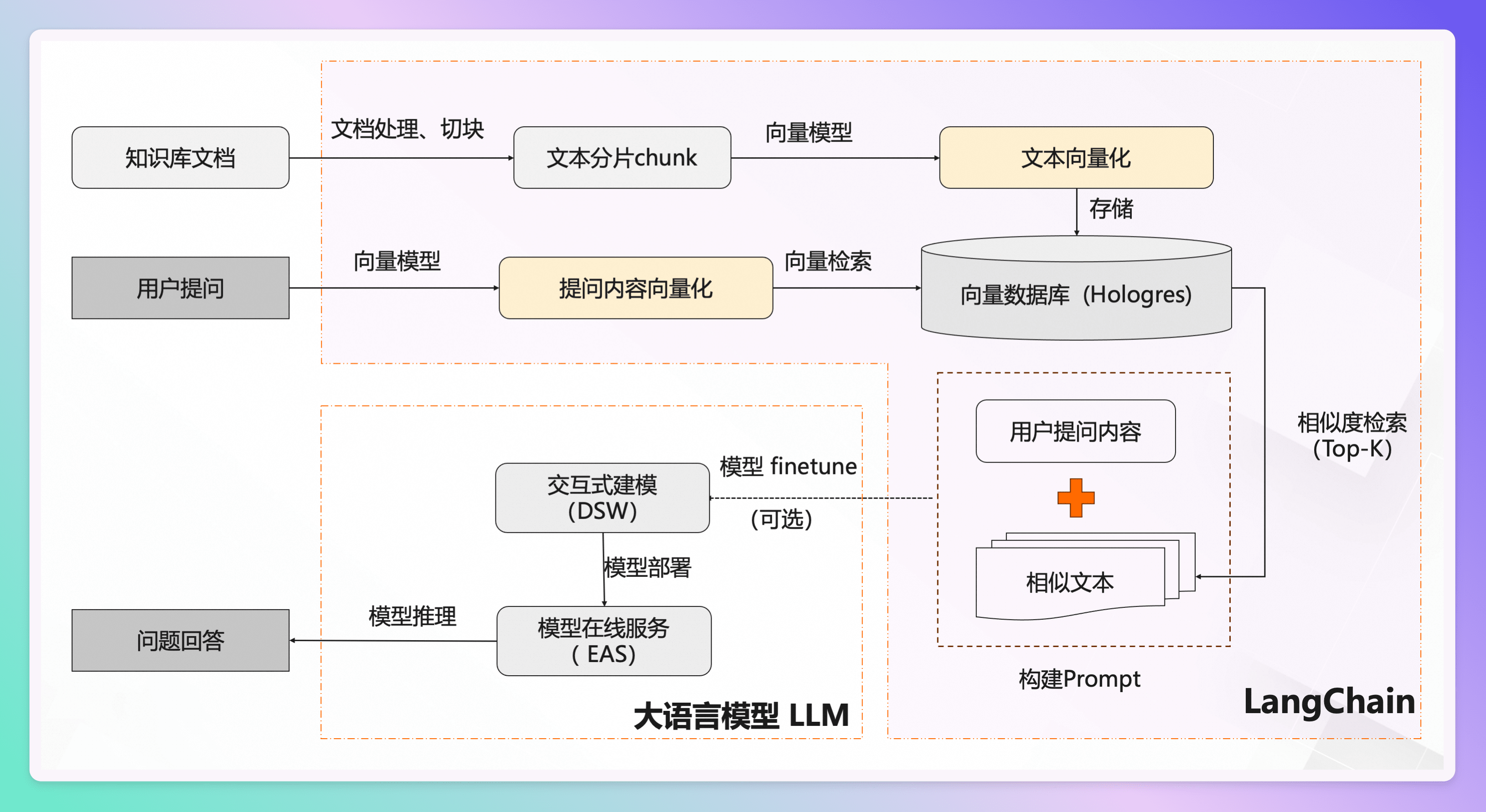
如上两张图所表现的整个过程,以及最终实现的功效,就称之为 rag。
两张图表达的意思是一致的,只是有部分表达有一些差异,原本我打算自己按照自己的理解绘制一下架构图,但看到金玉在前,自己也不再班门弄斧,特此标明出处,援引助解。
个人简约理解如下:
- 先将知识库内容切分,专有名词叫 chunk,此处有个关键点在于切分的块儿大小,将会影响每个块儿的内容,也会直接影响最终效果。
- 再把切分后的内容向量化存入向量数据库。
- 用户提问之后,先将问题在向量库中进行相似性检索,找出匹配度高的答案。
- 然后把查询出来的结果,包装好 Prompt。
- 最后调用大语言模型,让大语言模型基于上一步的结果进行分析并形成最终的答案,返回给用户。
上边的描述基本上也把整个流程给描述清楚了,现在对应每个步骤,也都有相应的技术解决方案,开源社区中很火的 langchain 则是针对如上步骤提供了整套封装的一个框架,如果对于 langchain 你也只是听说过没用过,甚至不了解它是个什么东西,那么这里我粗浅地讲,langchain 就是能够让你完成从文本处理,到转换向量与向量数据库的交互,再到承接用户提问的交互,再到与大语言模型的交互,所以如果你要构建一套 rag,那么基于 langchain 就可以做到,事实上,当下 GitHub 上很火的 rag 项目,大多也都是基于 langchain 来做的。
# rag 的问题
好了,经过上边的一些介绍,相信你对 rag 应该已经有了一些简单的认识,那么,概念清晰了,架构也有了,技术框架也有了,是不是投入精力学习框架,然后就能收获一个符合预期的 rag 系统了呢!
很不幸,并不能,当你按照开源社区一些框架给的教程,做出了一个 rag 的 demo 之后,你会发现,所呈现的效果,可能只有真正理想的效果 50%都不到。
为什么?
为什么会出现问答不理想的情况呢,这与整个实现 rag 流程中每个步骤细节相关,而且每个细节都是魔鬼,需要你花大量的精力学习研究,开发调试,测试验证,推到重来,循环往复,才可能得到一个大概够用的 rag 来,是的,认清现实,看完本篇,你知道 rag 是个什么东西就够了,不要轻易燃起深挖钻研 rag 的激情。
那么是什么问题,产生了这一不确定性呢?以下可能是需要考量的点。
- 如何处理原始数据?涉及到数据来源,数据格式,数据类型,乃至内容类型混合(比如一个 pdf 既有内容,又有表格,又有图片)等
- 如何合理地切分 Chunk?正如上文所言,不同大小的块儿最终会影响到检索到的结果
- 如何解决数据陈旧,并支持数据实时更新的能力?
- 如何选择 Embedding 模型?
- 大语言模型本地化的部署及维护
- 向量数据检索召回的设计
这里涉及的问题还有很多,每个问题单独拎出来都是一个专业领域的课题,而非单个人所能全面玩通玩精的。
因为我研究也还不够深入,关于这块儿的问题或者难点,推荐一篇非常有质量的文章:大模型 RAG 场景、数据、应用难点与解决 (opens new window)
# rag 领域开源项目
伴随着大语言模型的火爆,除去一开始火爆的那批套壳应用之外,后来者居上的,并且保持了持久热度的,恐怕就是 rag 领域的开源项目了,这里罗列一下我个人知道的 rag 领域相关的开源项目。
- dify (opens new window):一个开源的 LLM 应用开发平台。其直观的界面结合了 AI 工作流程、RAG 管道、代理功能、模型管理、可观察性功能等,让您可以快速从原型到生产。
- FastGPT (opens new window):一个基于 LLM 大语言模型的知识库问答系统,提供开箱即用的数据处理、模型调用等能力。同时可以通过 Flow 可视化进行工作流编排,从而实现复杂的问答场景!
- anything-llm (opens new window):一个全栈应用程序,使您能够将任何文档、资源或内容片段转换为任何法学硕士可以在聊天期间用作参考的上下文。该应用程序允许您选择要使用的法学硕士或矢量数据库,并支持多用户管理和权限。
- ragflow (opens new window):一款基于深度文档理解构建的开源 RAG(Retrieval-Augmented Generation)引擎。RAGFlow 可以为各种规模的企业及个人提供一套精简的 RAG 工作流程,结合大语言模型(LLM)针对用户各类不同的复杂格式数据提供可靠的问答以及有理有据的引用。
- MaxKB (opens new window):基于 LLM 大语言模型的知识库问答系统。开箱即用,支持快速嵌入到第三方业务系统。
- QAnything (opens new window):是致力于支持任意格式文件或数据库的本地知识库问答系统,可断网安装使用。您的任何格式的本地文件都可以往里扔,即可获得准确、快速、靠谱的问答体验。目前已支持格式: PDF(pdf),Word(docx),PPT(pptx),XLS(xlsx),Markdown(md),电子邮件(eml),TXT(txt),图片(jpg,jpeg,png),CSV(csv),网页链接(html)
# 最后
写着写着变成了一篇劝退文,然而这基本上也是我个人针对于 rag 的一个心路历程,从一开始听到这个词儿完全不懂,到通过一些学习了解,慢慢熟悉了一些概念,到上手部署,并实践了一些项目之后,开始对整个 rag 技术栈有了一定的认知,但随着这些认知的拓展,我开始发现,我不能在这上边磕太久了,我必须赶快把这篇粗浅认知的文写出来,然后把这个领域放下,转而把精力投注到更应该做的事情上。
自今年开年以来,我忙忙碌碌,几乎没有闲暇时刻,虽然没有做出什么亮眼的成绩,但常常感叹时间不够用,我还有很多东西需要学习,我还有很多事情要做,想要更美好的生活,必须付出更多的拼搏。


 |
|